MongoDB 核心概念与集群架构深度解析
简述
MongoDB 作为一款流行的 NoSQL 数据库,凭借其灵活的文档模型、高可扩展性和丰富的功能,在现代应用开发中占据着重要地位。本文将深入探讨 MongoDB 的核心概念,特别是其与传统关系型数据库(RDB)的区别,并详细解析 MongoDB 的各种集群架构,助你更好地理解和应用 MongoDB。
MongoDB 与关系型数据库(RDB)的核心概念对比
为了更好地理解 MongoDB,我们先将其核心概念与大家熟悉的关系型数据库进行对比:
| MongoDB | 关系型数据库 (RDB) | 说明 |
|---|---|---|
database | database | 数据库实例,包含多个集合/表 |
collection | table | 集合,类似于关系数据库中的表 |
document | row | 文档,类似于关系数据库中的行,是数据的基本单元 |
field | column | 字段,类似于关系数据库中的列 |
index | index | 索引,用于提高查询效率 |
_id | PRIMARY KEY (pk) | 文档的唯一标识符,自动创建且不可变 |
MongoDB 集群架构:高可用与可扩展性的基石
MongoDB 提供了多种集群方案,以满足不同场景下的高可用、数据冗余和读写分离需求。
1. 主从复制(Master-Slave)
主从复制是 MongoDB 最早提供的冗余策略,属于一种热备份方案。其主要特点如下:
- 架构:通常采用一主一从或一主多从的设计。
- Master(主节点):负责处理所有写操作和读操作。当数据发生变更时,会将操作日志(Oplog)同步到所有连接的 Slave 节点。
- Slave(从节点):默认为只读,从 Master 节点同步数据。从节点之间不直接通信。
- 应用场景:主要用于数据备份和读写分离,提升读取性能。
注意:主从复制在较新版本的 MongoDB 中已不推荐使用,副本集(Replica Set)是更优的选择。
2. 副本集(Replica Set)
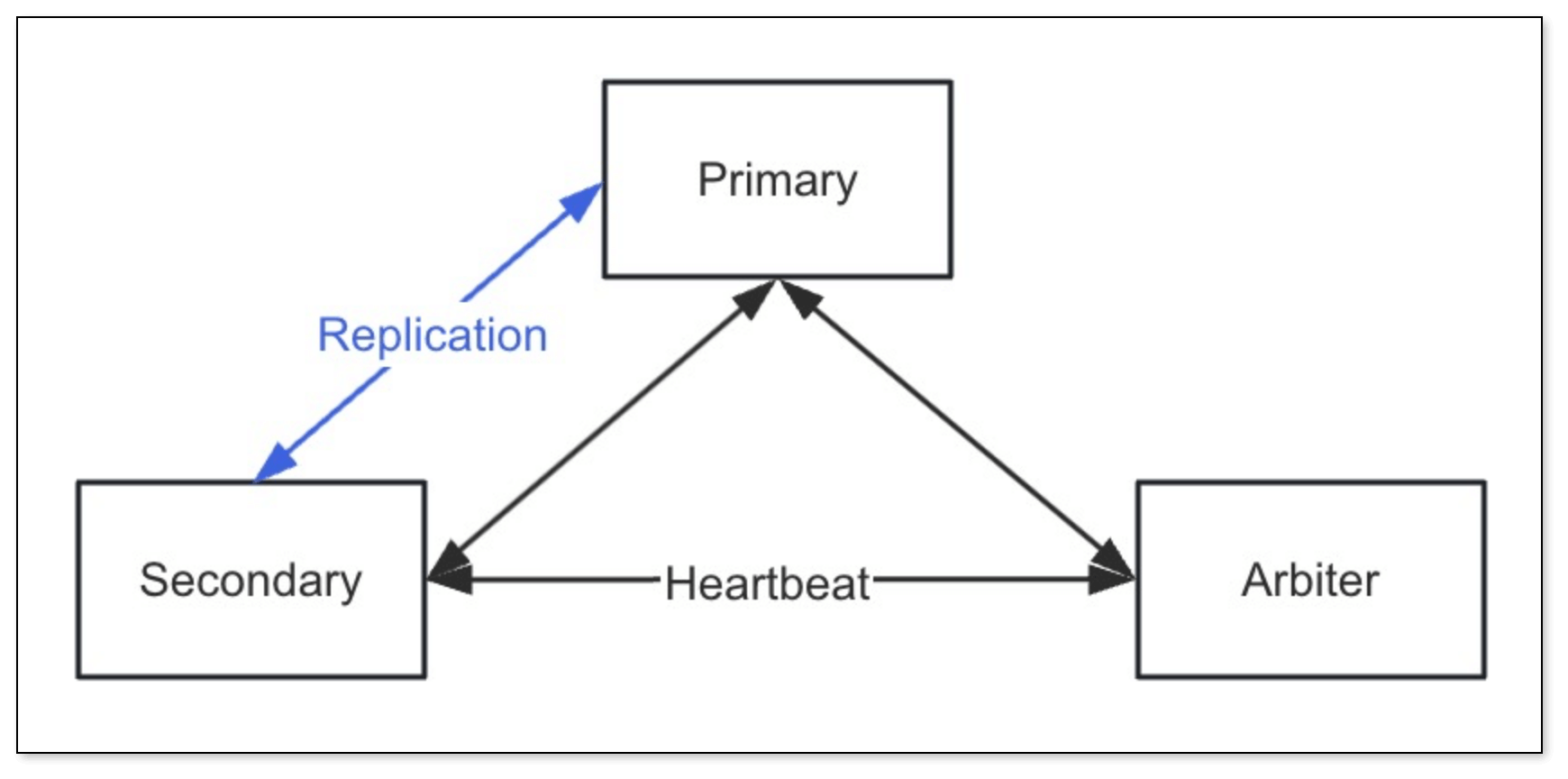
副本集是 MongoDB 官方推荐的高可用方案,旨在保证生产环境中数据的冗余和可靠性。
- 核心组成:
- Primary(主节点):一个副本集中有且仅有一个主节点,负责接收所有写请求,并将数据更改同步到所有 Secondary 节点。当 Primary 节点故障时,副本集会自动选举新的 Primary 节点。
- Secondary(副本节点):保存与主节点相同的数据副本。可以处理读请求,分担主节点压力。一个副本集可以有多个副本节点。
- Arbiter(仲裁节点) (可选):仲裁节点不保存数据副本,仅在选举过程中参与投票,帮助副本集在节点数量为偶数时也能顺利完成选举。一个副本集最多只能有一个仲裁节点。
- 优势:
- 数据冗余:通过在不同服务器上保存数据副本,防止单点故障导致数据丢失。
- 高可用性:主节点故障时自动进行故障转移,选举新的主节点,保证服务持续可用。
- 读写分离:读请求可以分散到副本节点,提高整体读取能力和系统负载。
3. 分片(Sharding)
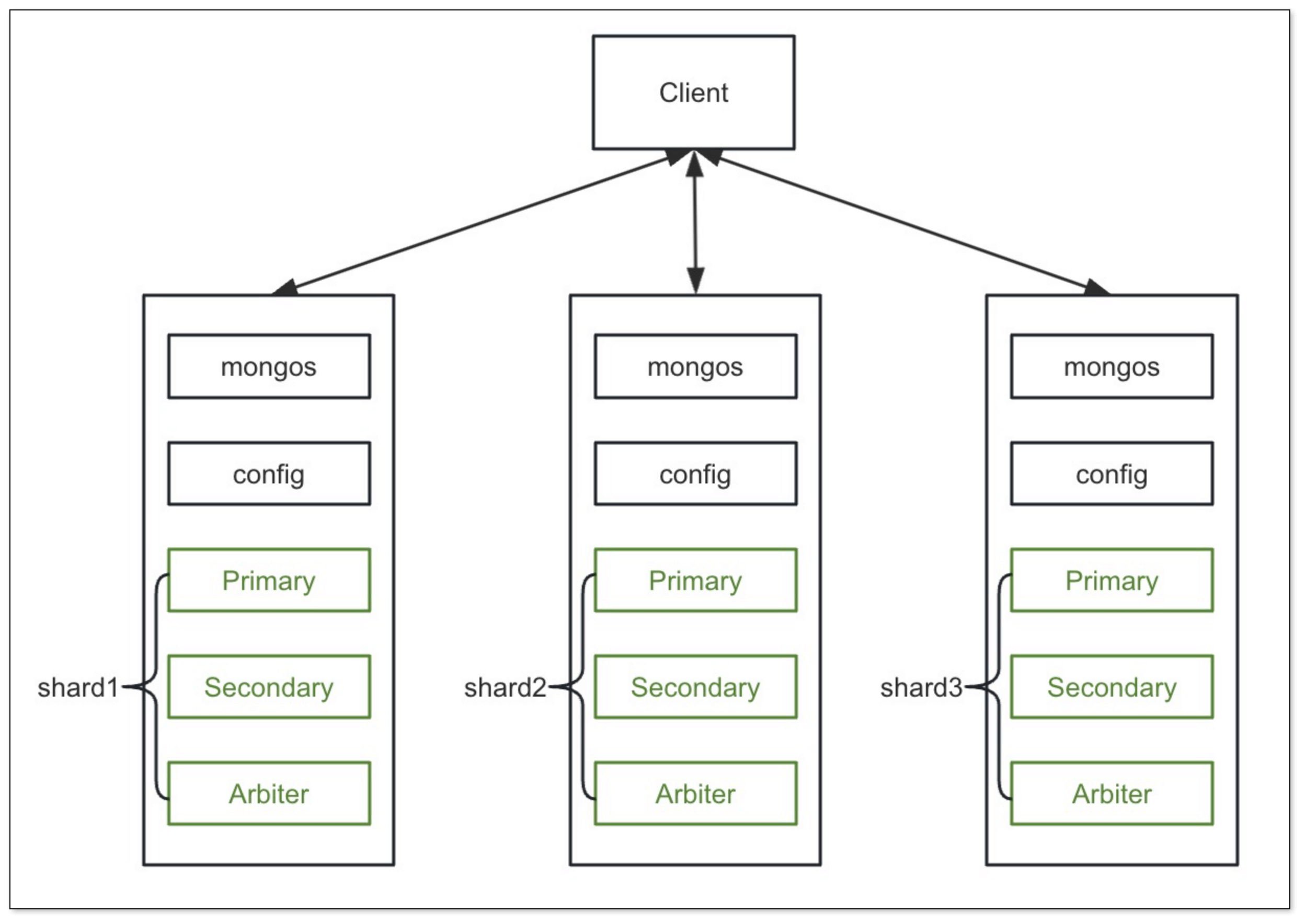
当数据集非常庞大,单个服务器难以承载时,分片就派上了用场。分片是将大型数据集水平分区成更小、更易于管理的数据片(Shard),并将这些数据片分散到不同的 MongoDB 服务器(分片节点)上。
- 核心组件:
- Shard(分片服务器):用于存储实际数据的分片。每个 Shard 可以是一个独立的 MongoDB 实例,或者(更常见且推荐)是一个副本集,以保证分片级别的高可用。从 MongoDB 3.6 版本开始,每个分片都必须是副本集。
- Config Server(配置服务器):存储集群的元数据信息,例如数据如何分布在各个 Shard 上(分片键、Chunk范围等)、用户信息等。配置服务器自身也需要高可用,因此从 MongoDB 3.4 版本开始,配置服务器必须部署为副本集。
- Routers (mongos):查询路由,是客户端应用程序与分片集群交互的入口。
mongos实例负责接收客户端的请求,根据配置服务器中的元数据将请求路由到正确的 Shard(s) 上,并聚合结果返回给客户端。一个分片集群可以有一个或多个mongos实例以实现负载均衡和高可用。
- 优势:
- 水平扩展:通过增加 Shard 节点来分散数据和负载,突破单机性能瓶颈。
- 高吞吐量:请求可以并行在多个 Shard 上处理。
在生产环境中,通常会将分片和副本集结合使用,即每个 Shard 本身就是一个副本集,从而同时实现数据的横向扩展和高可用性。
Oplog:MongoDB 数据同步的幕后功臣
Oplog(Operations Log,操作日志)是 MongoDB 实现数据同步(主从复制和副本集)的关键机制。
工作原理:当 Primary 节点(或 Master 节点)执行写操作后,会将这些操作记录到一个特殊的固定大小集合(Capped Collection)中,这个集合就是 Oplog。Secondary 节点(或 Slave 节点)会持续地从 Primary 节点拉取新的 Oplog 条目,并在本地重放这些操作,从而保持数据同步。
Oplog 集合位置:
- 主从架构:
local.oplog.$main - 副本集架构:
local.oplog.rs
- 主从架构:
特性:
- 固定大小 (Capped Collection):当 Oplog 集合达到其配置的上限大小时,会自动删除最旧的日志条目。因此,Oplog 的大小需要合理配置,以防止在 Secondary 节点宕机时间过长后,因 Oplog 被覆盖而无法追赶上 Primary 节点的情况。
- 幂等性:Oplog 中的操作必须是幂等的,这意味着即使一个操作在 Secondary 节点上被重复应用多次,其结果也应与应用一次相同。这保证了数据的一致性。
Oplog 条目格式示例:
{
"ts": Timestamp(1446011584, 2), // 操作的时间戳
"h": NumberLong("1687359108795812092"), // 全局唯一标识
"v": 2, // Oplog 版本信息
"op": "i", // 操作类型 (i: insert, u: update, d: delete, c: command, n: no-op)
"ns": "test.nosql", // 操作针对的命名空间 (database.collection)
"o": { "_id": ObjectId("563062c0b085733f34ab4129"), "name": "mongodb", "score": "100" } // 操作的具体内容 (如插入的文档)
// 对于更新操作,可能还会有 "o2": { "_id": ... } 字段,表示查询条件
}
Change Streams:实时捕获数据变更
Change Streams 是 MongoDB 提供的一种实时数据变更捕获机制。它允许应用程序订阅一个或多个集合、数据库或整个部署中的数据更改,并以接近实时的方式接收这些变更通知。
工作基础:Change Streams 利用了副本集的 Oplog。它会监控 Oplog 中的变更,并将这些变更转换为事件流推送给订阅的客户端。
使用场景:
- 实时分析
- 数据同步到其他系统
- 微服务间的事件通知
- 实时仪表盘
启用
preimage和postimage: 为了在 Change Streams 事件中捕获文档修改前(preimage)和修改后(postimage)的完整内容,需要在集合级别启用changeStreamPreAndPostImages选项:db.runCommand({
collMod: "yourCollectionName", // 替换为你的集合名称
changeStreamPreAndPostImages: { enabled: true }
});
这对于需要了解数据具体如何变化的场景非常有用。
MongoDB 常用操作示例
以下是一些 MongoDB 的基本操作命令,通过 mongosh(MongoDB Shell)执行。
1. 用户管理
创建用户并授予权限:
// 切换到 admin 数据库
use admin;
// 创建用户
db.createUser({
user: "myUserAdmin", // 用户名
pwd: "123456", // 密码
roles: [
{ role: "userAdminAnyDatabase", db: "admin" }, // 管理所有数据库的用户
{ role: "readWriteAnyDatabase", db: "admin" } // 对所有数据库有读写权限
]
});
2. 数据库操作
创建/切换数据库:
use myNewDatabase; // 如果数据库不存在,则在首次插入数据时创建注意:在 MongoDB 中,数据库和集合都是惰性创建的。只有当向集合中插入第一个文档或创建第一个索引时,数据库和集合才会被实际创建。
查看所有数据库:
show dbs;
// 或者
show databases;查看当前数据库:
db;删除当前数据库:
db.dropDatabase();
3. 集合 (Collection) 操作
创建集合:
// 显式创建集合
db.createCollection("myCollection");
// 也可以在插入第一个文档时隐式创建
db.anotherCollection.insertOne({ name: "Test" });查看当前数据库中的集合:
show collections;
// 或者
show tables; // 为了兼容 SQL 用户删除集合:
db.myCollection.drop();
4. 文档 (Document) 操作
插入文档
插入单个文档: insertOne()
返回一个包含新插入文档_id` 的对象。db.myCollection.insertOne({ name: "Alice", age: 30, city: "New York" });插入多个文档:insertMany()
返回一个包含新插入文档_id` 列表的对象。db.myCollection.insertMany([
{ name: "Bob", age: 24, city: "London" },
{ name: "Charlie", age: 35, city: "Paris" }
]);
查询文档
查询所有文档:
db.myCollection.find();按条件查询:
// 查询 name 为 "Alice" 的文档
db.myCollection.find({ name: "Alice" });
// 查询 age 大于 30 的文档
db.myCollection.find({ age: { $gt: 30 } });投影 (Projection) - 指定返回字段:
// 只返回 name 和 age 字段,默认包含 _id
db.myCollection.find({ city: "New York" }, { name: 1, age: 1 });
// 只返回 name 和 age 字段,不包含 _id
db.myCollection.find({ city: "New York" }, { name: 1, age: 1, _id: 0 });
在投影中,1 表示包含该字段,0 表示排除该字段。不能混合使用 1 和 0,唯一的例外是 _id 字段(默认包含,可以显式用 _id: 0 排除)。
查询单个文档:
db.myCollection.findOne({ name: "Bob" });高级查询操作:
跳过 (Skip) 和限制 (Limit):用于分页
// 查询前5条 age 大于 25 的文档,跳过前2条
db.myCollection.find({ age: { $gt: 25 } }).skip(2).limit(5);模糊查询 (正则表达式):
// 查询 name 以 "A" 开头的文档 (区分大小写)
db.myCollection.find({ name: /^A/ });
// 查询 name 包含 "li" 的文档 (不区分大小写)
db.myCollection.find({ name: /li/i });统计数量 (Count):
// 统计所有文档数量
db.myCollection.countDocuments(); // 推荐
// 按条件统计文档数量
db.myCollection.countDocuments({ city: "Paris" }); // 推荐
// 旧版 count (不推荐,某些情况下可能不准确)
// db.myCollection.count({ city: "Paris" });
更新文档
更新单个文档 (匹配到的第一个):
// 将 name 为 "Alice" 的文档的 age 更新为 31
db.myCollection.updateOne(
{ name: "Alice" }, // 查询条件
{ $set: { age: 31 } } // 更新操作
);
// 如果要替换整个文档 (除了_id),而不是只更新特定字段:
// db.myCollection.replaceOne({ name: "Alice" }, { name: "Alice Smith", age: 31, city: "New York" });更新多个文档:
// 将 city 为 "New York" 的所有文档的 status 更新为 "active"
db.myCollection.updateMany(
{ city: "New York" }, // 查询条件
{ $set: { status: "active" } } // 更新操作
);$inc操作符 (原子自增/自减):// 将 name 为 "Bob" 的文档的 age 增加 1
db.myCollection.updateOne({ name: "Bob" }, { $inc: { age: 1 } });Upsert 选项 (如果文档不存在则插入):
db.myCollection.updateOne(
{ name: "David" },
{ $set: { age: 40, city: "Berlin" } },
{ upsert: true } // 如果找不到 name 为 "David" 的文档,则插入新文档
);
删除文档
删除单个文档 (匹配到的第一个):
db.myCollection.deleteOne({ name: "Charlie" });删除多个文档:
// 删除所有 age 小于 25 的文档
db.myCollection.deleteMany({ age: { $lt: 25 } });删除集合中所有文档:
db.myCollection.deleteMany({}); // 删除所有文档,但保留集合本身和索引注意:
db.myCollection.drop()会删除整个集合,包括索引。
MongoDB 安装与副本集配置示例 (Docker Compose)
以下是一个使用 Docker Compose 部署 MongoDB 副本集的示例。
mongo-docker-compose.yml 文件: (假设与 mongodb.key 文件在同一目录)
version: "3"
services:
#主节点
mongodb1:
image: mongo:latest
container_name: mongo1
restart: always
ports:
- 27017:27017
environment:
- MONGO_INITDB_ROOT_USERNAME=root
- MONGO_INITDB_ROOT_PASSWORD=mongodb@evescn
command: mongod --replSet rs0 --keyFile /mongodb.key
volumes:
- /etc/localtime:/etc/localtime
- /Users/juantu/Desktop/mongodb/mongo1/data:/data/db
- /Users/juantu/Desktop/mongodb/mongo1/configdb:/data/configdb
- /Users/juantu/Desktop/mongodb/mongo1/mongodb.key:/mongodb.key
networks:
- mongoNet
entrypoint:
- bash
- -c
- |
chmod 400 /mongodb.key
chown 999:999 /mongodb.key
exec docker-entrypoint.sh $$@
# 副节点
mongodb2:
image: mongo:latest
container_name: mongo2
restart: always
ports:
- 27018:27017
environment:
- MONGO_INITDB_ROOT_USERNAME=root
- MONGO_INITDB_ROOT_PASSWORD=mongodb@evescn
command: mongod --replSet rs0 --keyFile /mongodb.key
volumes:
- /etc/localtime:/etc/localtime
- /Users/juantu/Desktop/mongodb/mongo2/data:/data/db
- /Users/juantu/Desktop/mongo2/configdb:/data/configdb
- /Users/juantu/Desktop/mongodb/mongo2/mongodb.key:/mongodb.key
networks:
- mongoNet
entrypoint:
- bash
- -c
- |
chmod 400 /mongodb.key
chown 999:999 /mongodb.key
exec docker-entrypoint.sh $$@
# 副节点
mongodb3:
image: mongo:latest
container_name: mongo3
restart: always
ports:
- 27019:27017
environment:
- MONGO_INITDB_ROOT_USERNAME=root
- MONGO_INITDB_ROOT_PASSWORD=mongodb@evescn
command: mongod --replSet rs0 --keyFile /mongodb.key
volumes:
- /etc/localtime:/etc/localtime
- /Users/juantu/Desktop/mongodb/mongo3/data:/data/db
- /Users/juantu/Desktop/mongodb/mongo3/configdb:/data/configdb
- /Users/juantu/Desktop/mongodb/mongo3/mongodb.key:/mongodb.key
networks:
- mongoNet
entrypoint:
- bash
- -c
- |
chmod 400 /mongodb.key
chown 999:999 /mongodb.key
exec docker-entrypoint.sh $$@
networks:
mongoNet:
driver: bridge
mongodb.key 文件 (密钥文件): 首先,你需要生成一个密钥文件。这个文件用于副本集成员之间的内部认证。
openssl rand -base64 756 > mongodb.key
chmod 400 mongodb.key
将生成的 mongodb.key 文件内容复制到你的 mongodb.key 文件中。
启动和配置副本集步骤:
启动 Docker Compose 服务:
docker-compose -f mongo-docker-compose.yml up -d初始化副本集: 连接到其中一个 MongoDB 实例 (例如
mongo1) 并初始化副本集。你需要先创建一个管理员用户,然后再初始化。# 连接到 mongo1 (初始时可能不需要用户密码,因为 auth 还未完全强制执行直到副本集配置完成)
mongosh --host mongo1:27017 --username root --password mongodb@evescn --eval
# 初始化副本集
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo1:27017", priority: 2 }, // priority 越高的越容易成为主节点
{ _id: 1, host: "mongo2:27017", priority: 1 },
{ _id: 2, host: "mongo3:27017", priority: 1 }
]
});
# 等待副本集初始化完成,提示符会变为 "rs0 [PRIMARY]>" 或类似。
# 检查副本集状态
rs.status();为 Change Streams 启用 Pre- and Post-Images (可选): 如果你需要使用 Change Streams 并获取文档修改前后的完整镜像:
// 在 mongosh 中连接到你的数据库
use yourDatabaseName; // 切换到你的目标数据库
db.runCommand({
collMod: "yourCollectionName", // 替换为你的集合名称
changeStreamPreAndPostImages: { enabled: true }
});
总结
MongoDB 凭借其灵活的数据模型和强大的横向扩展能力,成为了众多应用的首选数据库。
理解其与关系型数据库的差异、掌握副本集和分片等核心集群架构,以及熟悉 Oplog 和 Change Streams 等高级特性,对于高效地设计、部署和维护 MongoDB 系统至关重要。
希望本文能为你提供有价值的参考。