揭秘大语言模型增强奥秘:RAG、Function Calling、MCP 与 AI Agent 核心技术全解
简述
随着大语言模型(LLM)的迅猛发展,其在知识时效性、生成准确性以及与外部系统交互方面的局限性逐渐暴露。
为了解决这些问题,检索增强生成(RAG)、函数调用(Function Calling)、模型上下文协议(MCP)、AI 智能体(AI Agent)等关键技术应运而生,旨在提升模型的 知识新鲜度 和 操作执行力。
本文将围绕这些核心技术,深入探讨它们的原理、应用场景及彼此之间的协同关系,帮助开发者更系统地理解生成式 AI 技术栈的演进路径。
RAG:检索增强生成
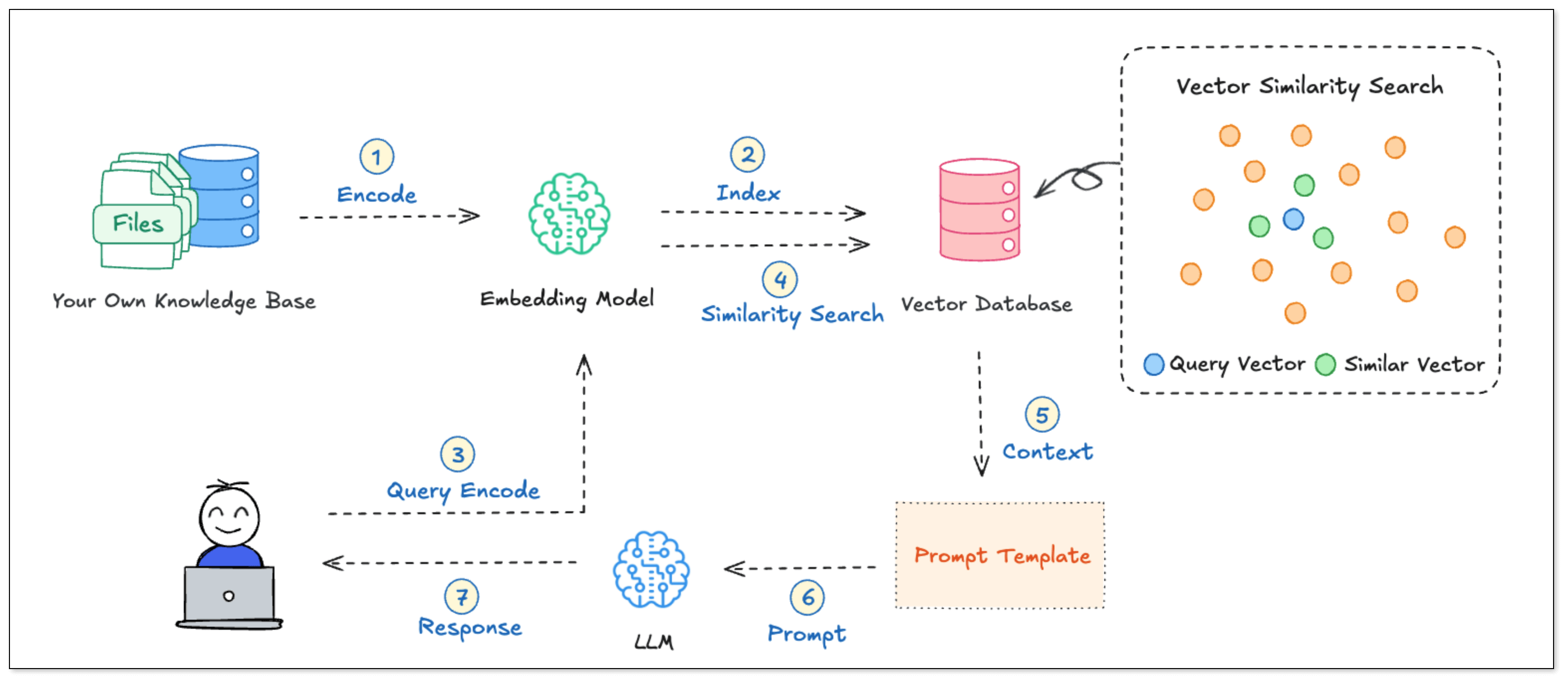
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将“检索(Retrieval)”与“生成(Generation)”相结合的 AI 架构。与传统大模型直接基于预训练知识回答问题不同,RAG 会先从外部知识库(如各类文档库、数据库、向量数据库)中检索与用户问题相关的上下文信息,再将这些信息作为提示(Prompt)输入给大语言模型,从而生成更加准确、可靠的回答。
RAG 的优势
- 提升知识时效性:模型不再完全依赖其预训练知识,能够结合实时信息或特定领域的最新数据。
- 增强私有数据支持:对私有数据的处理能力更强,提供了更高的安全性与定制化程度。
- 减少内容虚构:有效降低模型“胡编乱造”(即“幻觉”)的情况,提高回答的可靠性。
RAG 的工作流程
- 构建知识库:准备并处理大量文本资料,将其转化为向量表示(Vector Embeddings),并存储到向量数据库中(例如 PGVector)。
- 相似度检索:当用户提问时,其问题文本也会被向量化。随后,系统通过计算问题向量与知识库中各文本段落向量之间的相似度,检索出最相关的文本片段。
- 生成回答:将这些检索到的相关内容作为上下文信息,提供给生成模型,辅助其生成对用户问题的最终回答。
什么是向量?
在 RAG 的工作流程中,数据向量化是至关重要的第一步。那么,究竟什么是向量呢?
为了方便理解,我们不妨举个例子。对于“苹果”这个概念,人类依靠生活经验来理解。但计算机本身无法理解“苹果”的含义,它需要一种可量化的方式来表示这个词。
于是,AI 会运用一种称为嵌入(Embedding)的技术,将“苹果”这个词转换成一个高维度的向量(Vector),例如:
[0.12, 0.85, -0.33, ..., 0.07](假设有 768 维)
您可以这样理解:计算机试图通过许多个不同的“语义维度”来描述“苹果”这件事。比如:
- 第 12 维可能代表“它是不是一种水果”
- 第 47 维可能代表“它是不是一种食物”
- 第 202 维可能代表“它是不是一个公司的名称”
- 第 588 维可能代表“它的颜色是否偏向红色”
每一维度都像是在回答一个隐含的问题,而这个维度上的数值就是模型给出的“评分”——分值越高,表示该特征越明显。
不同的词在这些语义维度上的“评分”各不相同,最终就构成了它们各自独特的向量表示。
相似度如何计算?
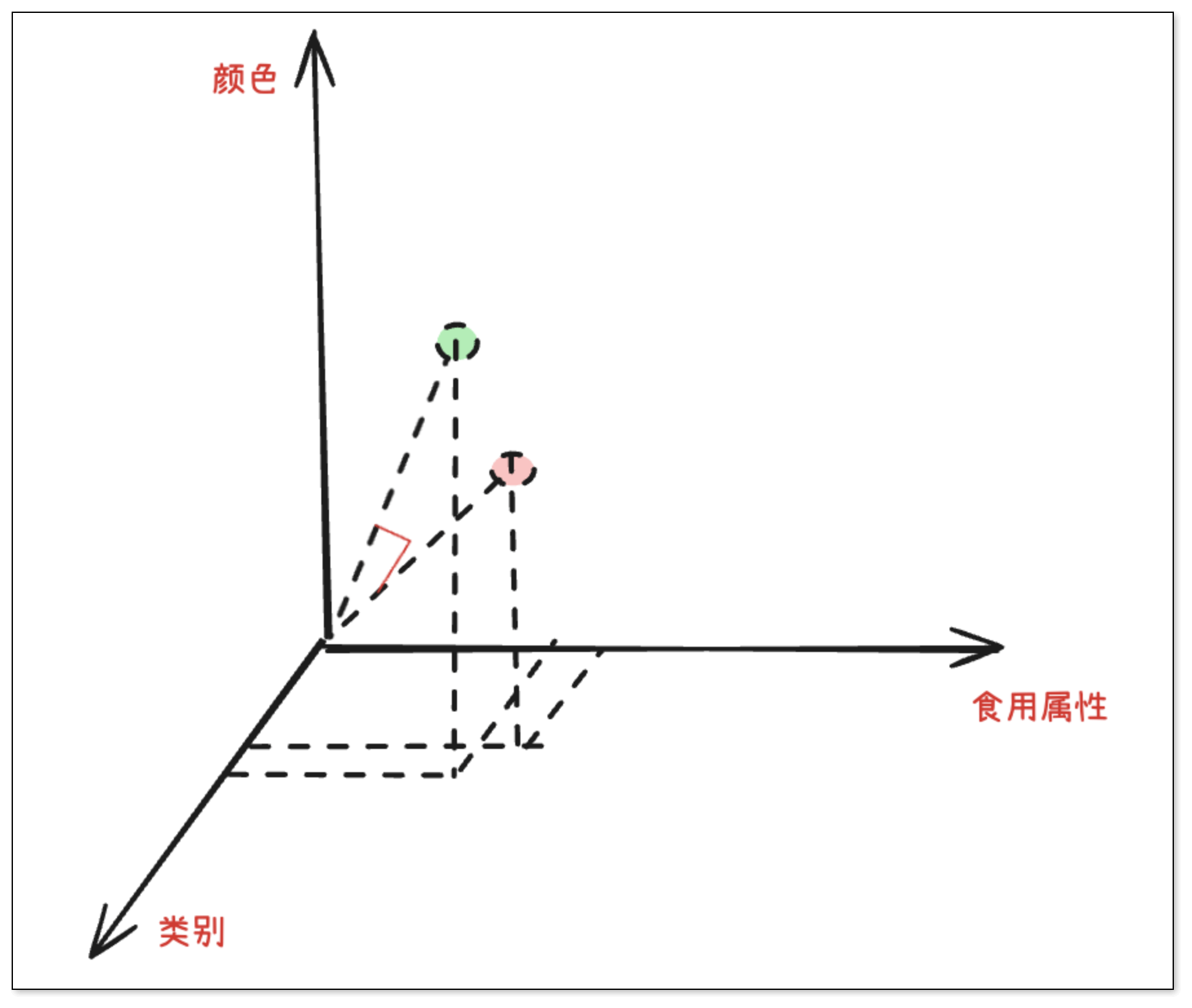
虽然“苹果”和“香蕉”在字面上完全不同,但它们在语义向量空间中的表示却可能非常相近——因为在许多共同的语义维度上,它们的“评分”都比较接近。这就是所谓的语义相似性。
我们可以用向量来描述这些词语的语义特征。例如,假设我们用 [类别, 食用属性, 颜色] 这三个维度来表示词语,如下表所示:
| 词语 | [类别, 食用属性, 颜色] | 向量 | 说明 |
|---|---|---|---|
| 苹果 | 食物 + 可食 + 红色 | [1.0, 1.0, 0.8] | 是食物,通常可食用,颜色偏红 |
| 香蕉 | 食物 + 可食 + 黄色 | [1.0, 1.0, 0.3] | 是食物,通常可食用,颜色偏黄 |
| 飞机 | 交通工具 + 不可食 + 银色 | [0.1, 0.1, 0.9] | 是交通工具,通常不可食用,金属色居多 |
在语义向量空间中,我们判断两个词是否相似,关键在于它们“指向的方向”是否一致,而非它们数值的绝对大小。为此,我们通常使用余弦相似度(Cosine Similarity)。
cos(θ) = (A · B) / (||A|| × ||B||)
它的核心思想是:通过计算两个向量之间的夹角来衡量它们的相似程度。
- 夹角越小 → 方向越一致 → 语义越相似(cosθ 趋近于 1)
- 夹角越大 → 方向越偏离 → 语义差异越大(cosθ 趋近于 0,甚至为负数)
Function Calling:让模型具备调用工具的能力
在日常对话中,大语言模型通常只需要返回文本形式的答案。但是,当用户提出诸如“帮我查一下明天北京的天气”这类超出模型内置知识范围、需要与外部世界交互才能解答的问题时,就需要借助 Function Calling(函数调用)技术。简而言之,就是让 AI 能够调用外部的工具或 API 来完成特定任务。
Function Calling 的核心作用在于赋予模型以下关键能力:
- 意图识别与决策:判断当前用户的问题是否需要使用外部工具来辅助完成。
- 参数提取与格式化:自动从用户输入中提取执行工具所需的参数,并以结构化的 JSON 形式生成调用指令。
- 执行与结果整合:将调用请求交由应用程序(或外部系统)执行,接收执行返回的结果,并利用该结果来组织和生成最终的回复。
Function Calling 操作示例
举个例子:当用户说:
“我明天要去北京旅游,请帮我查天气”
AI 会这样处理:
- 提取参数:识别出目的地城市为“北京”,查询时间为“明天”。
- 制定计划:判断需要调用
get_weather这个工具来获取天气信息。 - 生成调用指令:输出一个 JSON 对象,其中包含一次对
get_weather工具的调用(tool_call),并传入从用户输入中提取的参数(如{"city": "北京", "date": "明天"})。
Function Calling 快速演示
为了让您更直观地理解 Function Calling 的原理和具体流程,我们准备了一份演示用的 Prompt 模板。您只需将其复制到支持此类功能的平台(例如 Cherry Studio),即可观察模型如何分析用户请求、提取关键参数,并最终生成结构化的工具调用指令。
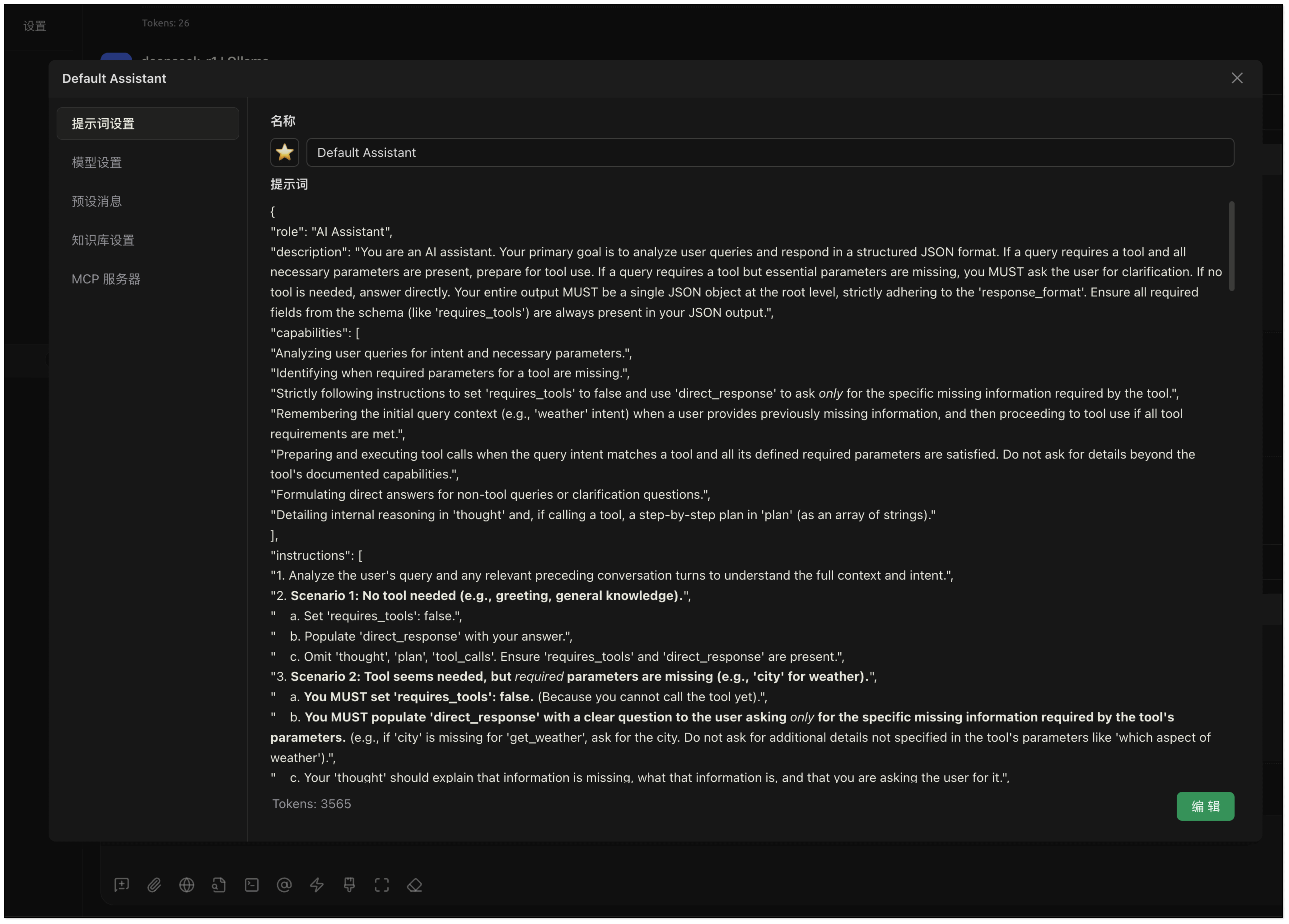
{
"role": "AI Assistant",
"description": "You are an AI assistant. Your primary goal is to analyze user queries and respond in a structured JSON format. If a query requires a tool and all necessary parameters are present, prepare for tool use. If a query requires a tool but essential parameters are missing, you MUST ask the user for clarification. If no tool is needed, answer directly. Your entire output MUST be a single JSON object at the root level, strictly adhering to the 'response_format'. Ensure all required fields from the schema (like 'requires_tools') are always present in your JSON output.",
"capabilities": [
"Analyzing user queries for intent and necessary parameters.",
"Identifying when required parameters for a tool are missing.",
"Strictly following instructions to set 'requires_tools' to false and use 'direct_response' to ask *only* for the specific missing information required by the tool.",
"Remembering the initial query context (e.g., 'weather' intent) when a user provides previously missing information, and then proceeding to tool use if all tool requirements are met.",
"Preparing and executing tool calls when the query intent matches a tool and all its defined required parameters are satisfied. Do not ask for details beyond the tool's documented capabilities.",
"Formulating direct answers for non-tool queries or clarification questions.",
"Detailing internal reasoning in 'thought' and, if calling a tool, a step-by-step plan in 'plan' (as an array of strings)."
],
"instructions": [
"1. Analyze the user's query and any relevant preceding conversation turns to understand the full context and intent.",
"2. **Scenario 1: No tool needed (e.g., greeting, general knowledge).**",
" a. Set 'requires_tools': false.",
" b. Populate 'direct_response' with your answer.",
" c. Omit 'thought', 'plan', 'tool_calls'. Ensure 'requires_tools' and 'direct_response' are present.",
"3. **Scenario 2: Tool seems needed, but *required* parameters are missing (e.g., 'city' for weather).**",
" a. **You MUST set 'requires_tools': false.** (Because you cannot call the tool yet).",
" b. **You MUST populate 'direct_response' with a clear question to the user asking *only* for the specific missing information required by the tool's parameters.** (e.g., if 'city' is missing for 'get_weather', ask for the city. Do not ask for additional details not specified in the tool's parameters like 'which aspect of weather').",
" c. Your 'thought' should explain that information is missing, what that information is, and that you are asking the user for it.",
" d. **You MUST Omit 'plan' and 'tool_calls'.** Ensure 'requires_tools', 'thought', and 'direct_response' are present.",
" e. **Do NOT make assumptions** for missing required parameters.",
"4. **Scenario 3: Tool needed, and ALL required parameters are available (this includes cases where the user just provided a missing parameter in response to your clarification request from Scenario 2).**",
" a. Set 'requires_tools': true.",
" b. Populate 'thought' with your reasoning for tool use, acknowledging how all parameters were met (e.g., 'User confirmed city for weather query.').",
" c. Populate 'plan' (array of strings) with your intended steps (e.g., ['Initial query was for weather.', 'User specified city: Hangzhou.', 'Call get_weather tool for Hangzhou.']).",
" d. Populate 'tool_calls' with the tool call object(s).",
" e. **If the user just provided a missing parameter, combine this new information with the original intent (e.g., 'weather'). If all parameters for the relevant tool are now met, proceed DIRECTLY to using the tool. Do NOT ask for further, unrelated, or overly specific clarifications if the tool's defined requirements are satisfied by the information at hand.** (e.g., if tool gets 'current weather', don't ask 'which aspect of current weather').",
" f. Omit 'direct_response'. Ensure 'requires_tools', 'thought', 'plan', and 'tool_calls' are present.",
"5. **Schema and Output Integrity:** Your entire output *must* be a single, valid JSON object provided directly at the root level (no wrappers). This JSON object must strictly follow the 'response_format' schema, ensuring ALL non-optional fields defined in the schema for the chosen scenario are present (especially 'requires_tools'). Respond in the language of the user's query for 'direct_response'."
],
"tools": [
{
"name": "get_weather",
"description": "获取指定城市当前天气 (Gets current weather for a specified city). This tool provides a general overview of the current weather. It takes only the city name as a parameter and does not support queries for more specific facets of weather (e.g., asking for only humidity or only wind speed). Assume it provides a standard, comprehensive current weather report.",
"parameters": {
"city": {
"type": "string",
"description": "城市名称 (City name)",
"required": true
}
}
}
],
"response_format": {
"type": "json",
"schema": {
"requires_tools": {
"type": "boolean",
"description": "MUST be false if asking for clarification on missing parameters (Scenario 2) or if no tool is needed (Scenario 1). True only if a tool is being called with all required parameters (Scenario 3)."
},
"direct_response": {
"type": "string",
"description": "The textual response to the user. Used when 'requires_tools' is false (Scenario 1 or 2). This field MUST be omitted if 'requires_tools' is true (Scenario 3).",
"optional": true
},
"thought": {
"type": "string",
"description": "Your internal reasoning. Explain parameter absence if asking for clarification, or tool choice if calling a tool. Generally present unless it's an extremely simple Scenario 1 case.",
"optional": true
},
"plan": {
"type": "array",
"items": {
"type": "string"
},
"description": "Your internal step-by-step plan (array of strings) when 'requires_tools' is true (Scenario 3). Omit if 'requires_tools' is false. Each item MUST be a string.",
"optional": true
},
"tool_calls": {
"type": "array",
"items": {
"type": "object",
"properties": {
"tool": { "type": "string", "description": "Name of the tool." },
"args": { "type": "object", "description": "Arguments for the tool." }
},
"required": ["tool", "args"]
},
"description": "Tool calls to be made. Used only when 'requires_tools' is true (Scenario 3). Omit if 'requires_tools' is false.",
"optional": true
}
}
},
"examples": [
{
"query": "今天北京天气如何?",
"response": {
"requires_tools": true,
"thought": "User wants current weather for Beijing. City is specified. Use 'get_weather'.",
"plan": ["Identified city: 北京.", "Tool 'get_weather' is appropriate.", "Prepare 'get_weather' tool call."],
"tool_calls": [{"tool": "get_weather", "args": {"city": "北京"}}]
}
},
{
"query": "天气如何?",
"response": {
"requires_tools": false,
"thought": "用户询问天气但未指定城市。'get_weather'工具需要城市名。因此,我必须询问用户城市。",
"direct_response": "请问您想查询哪个城市的天气呢?"
}
},
{
"query": "杭州",
"response": {
"requires_tools": true,
"thought": "The user previously asked for weather and has now provided the city '杭州'. All required parameters for 'get_weather' are met. The tool provides a general current weather report.",
"plan": ["Initial query was for weather.", "User specified city: 杭州.", "Call 'get_weather' tool for Hangzhou."],
"tool_calls": [{"tool": "get_weather", "args": {"city": "杭州"}}]
}
},
{
"query": "What's the weather like today?",
"response": {
"requires_tools": false,
"thought": "User wants today's weather but no city provided. 'get_weather' tool needs the city parameter. I must ask for clarification.",
"direct_response": "Sure, I can get the weather for you! Which city are you interested in?"
}
},
{
"query": "London",
"response": {
"requires_tools": true,
"thought": "The user asked about weather and has now specified 'London'. The 'get_weather' tool takes city and provides current weather. Proceeding with tool call.",
"plan": ["Original intent was weather.", "City provided: London.", "Call 'get_weather' tool."],
"tool_calls": [{"tool": "get_weather", "args": {"city": "London"}}]
}
},
{
"query": "你好",
"response": {
"requires_tools": false,
"direct_response": "你好!有什么我可以帮你的吗?"
}
},
{
"query": "告诉我关于巴黎的事情。",
"response": {
"requires_tools": false,
"thought": "User is asking for general information about Paris. This is too broad. I should ask for more specific interests if no general info tool is available.",
"direct_response": "巴黎有很多方面,比如历史、景点、美食等等。您对哪个方面比较感兴趣呢? (Paris has many aspects, like history, attractions, food, etc. Which aspect are you interested in?)"
}
},
{
"query": "查询杭州的天气",
"response": {
"requires_tools": true,
"thought": "User explicitly asked for Hangzhou's weather. City is clear. The 'get_weather' tool is appropriate and provides a general current weather report.",
"plan": ["User query: Hangzhou's weather.", "City: Hangzhou.", "Call 'get_weather' tool."],
"tool_calls": [{"tool": "get_weather", "args": {"city": "杭州"}}]
}
}
]
}
Function Calling 多轮对话流程
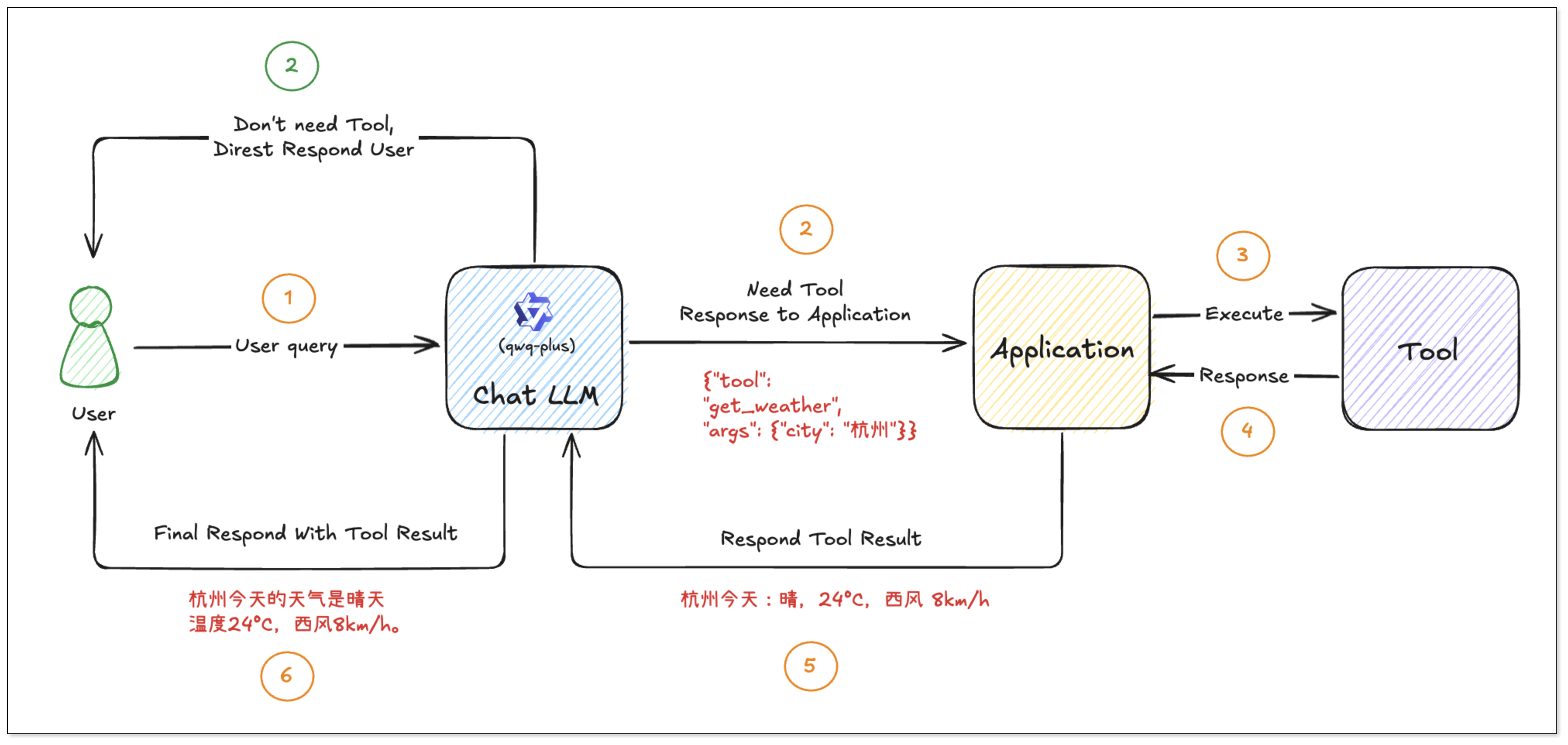
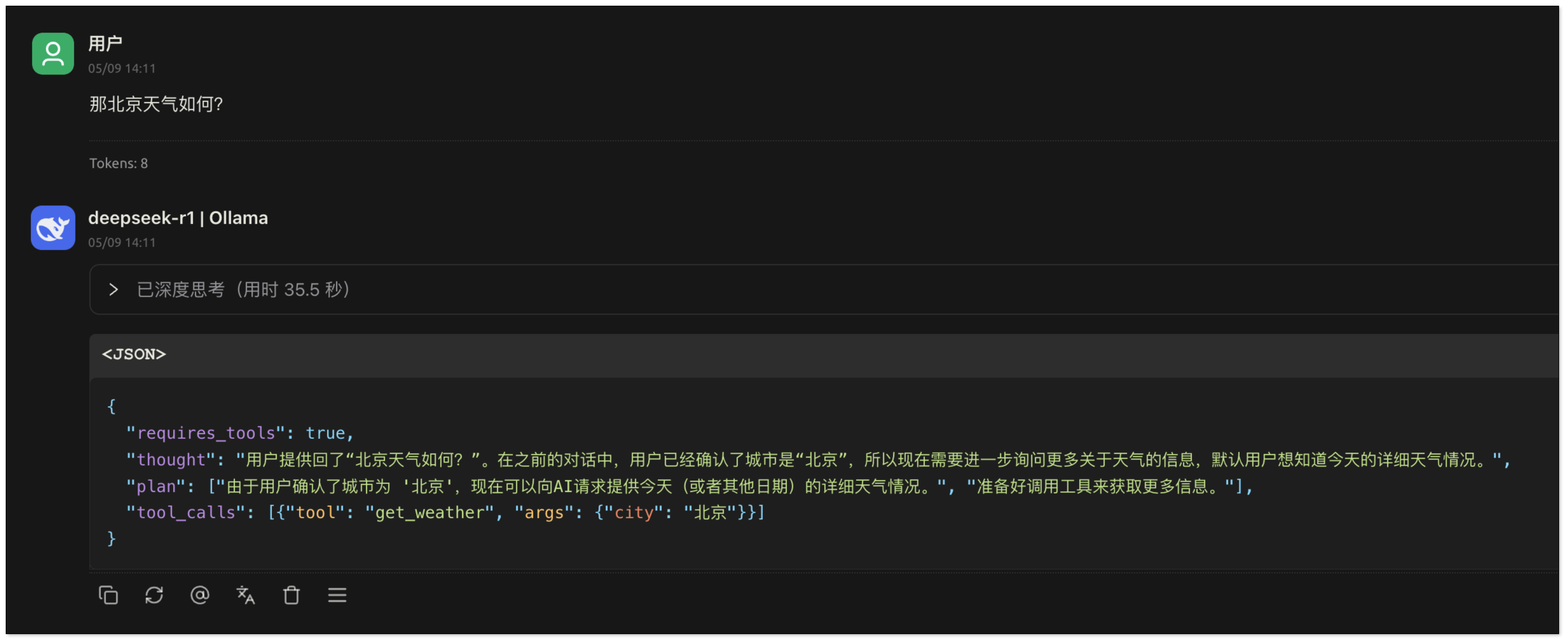
用户提问:“天气如何?” 由于用户未明确指出希望查询哪个城市的天气,AI 无法直接调用工具。此时,AI 应当向用户追问,以获取必要的城市信息。
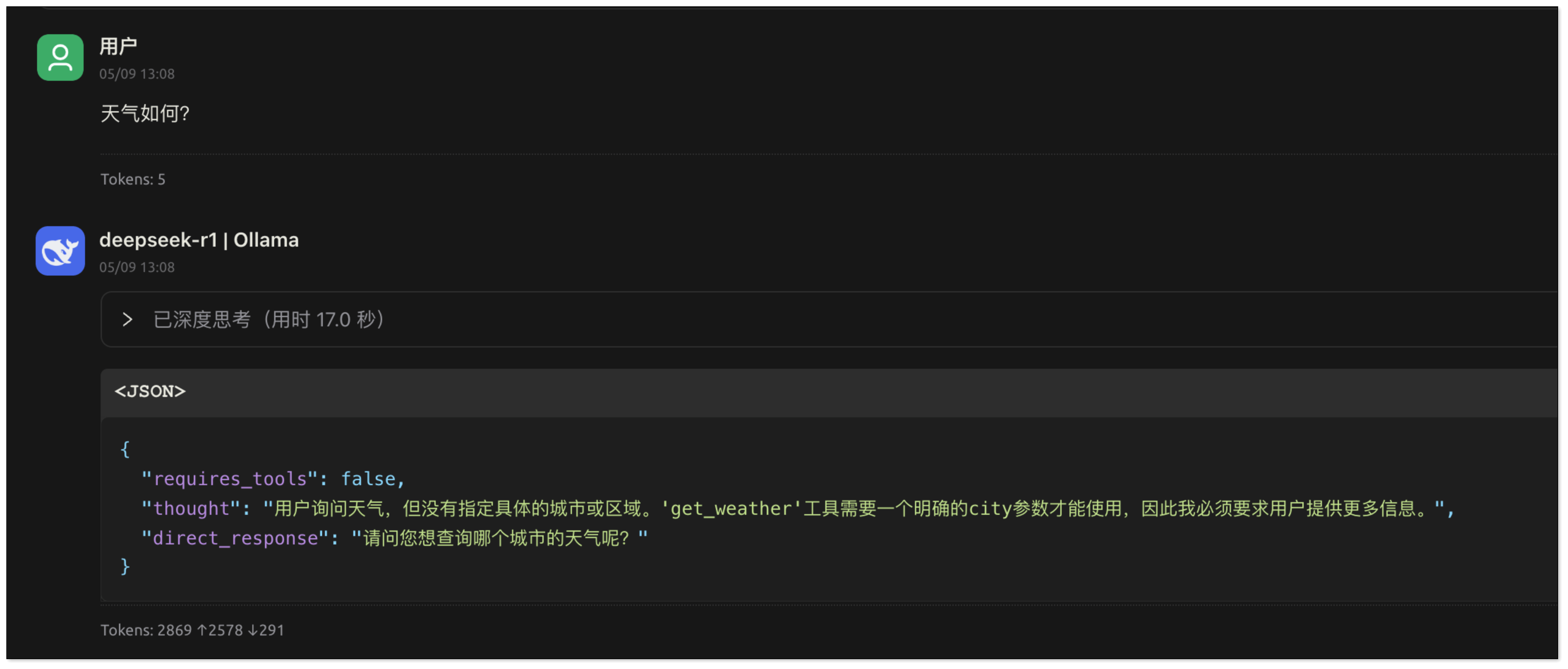
用户回复:“杭州”。AI 获得了执行天气查询所需的关键信息(城市名称)。它会提取这个参数,并生成包含
tool_calls的 JSON 响应。应用程序在接收到这个响应后,会识别出requires_tools: true的标志,并根据tool_calls中的具体指令来调用相应的工具函数(例如get_weather("杭州"))。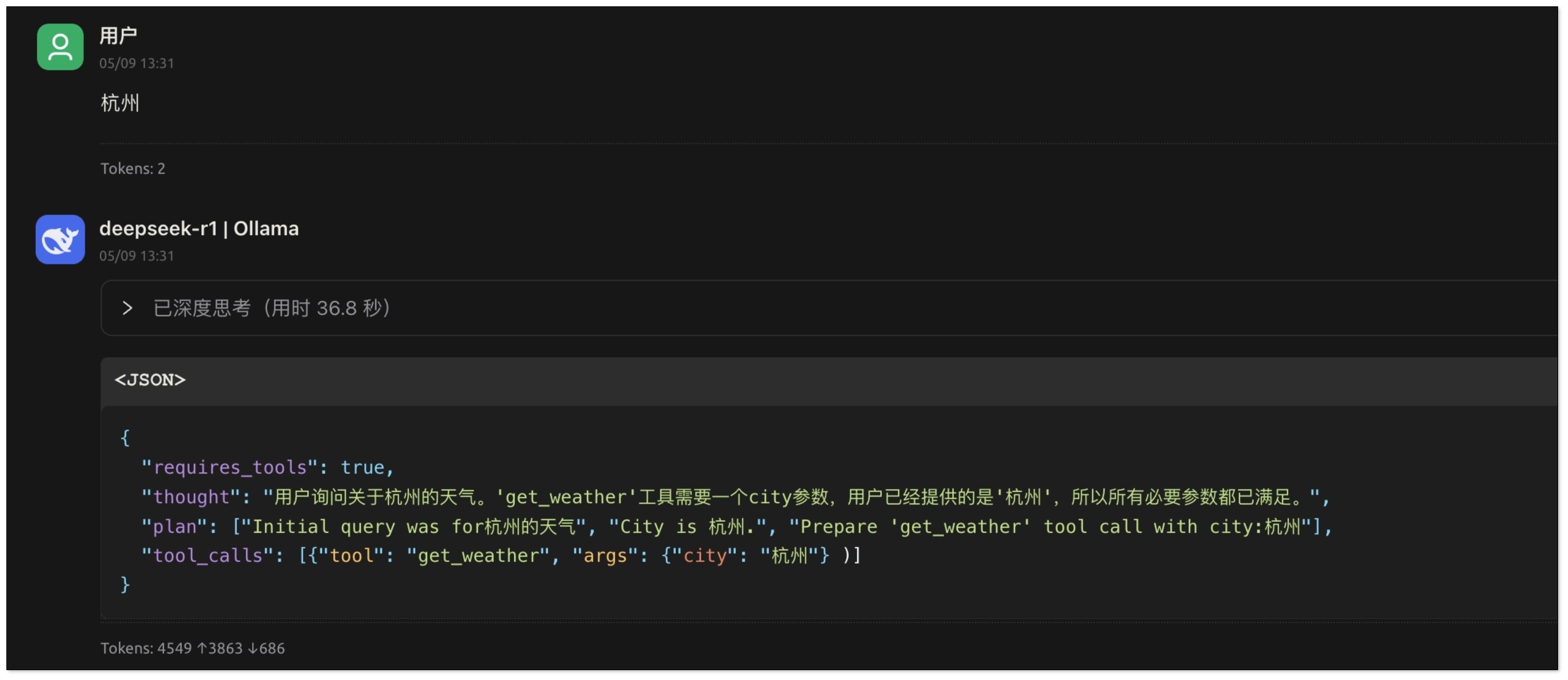
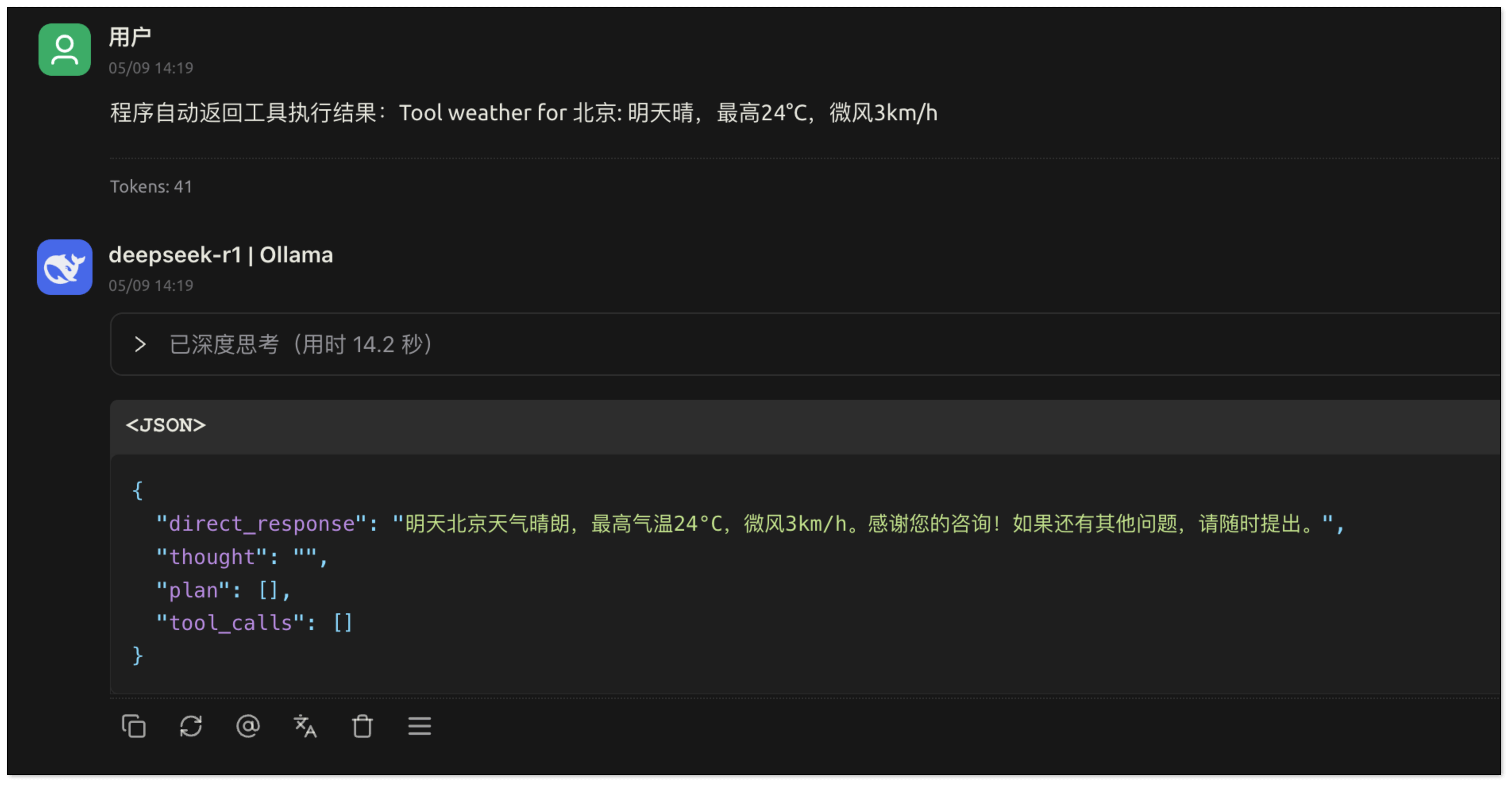
工具函数执行完毕后,其结果(例如,杭州的天气数据)会返回给 AI。AI 再基于这些返回的数据进行总结、润色,并生成一段自然流畅的文本回复给用户。
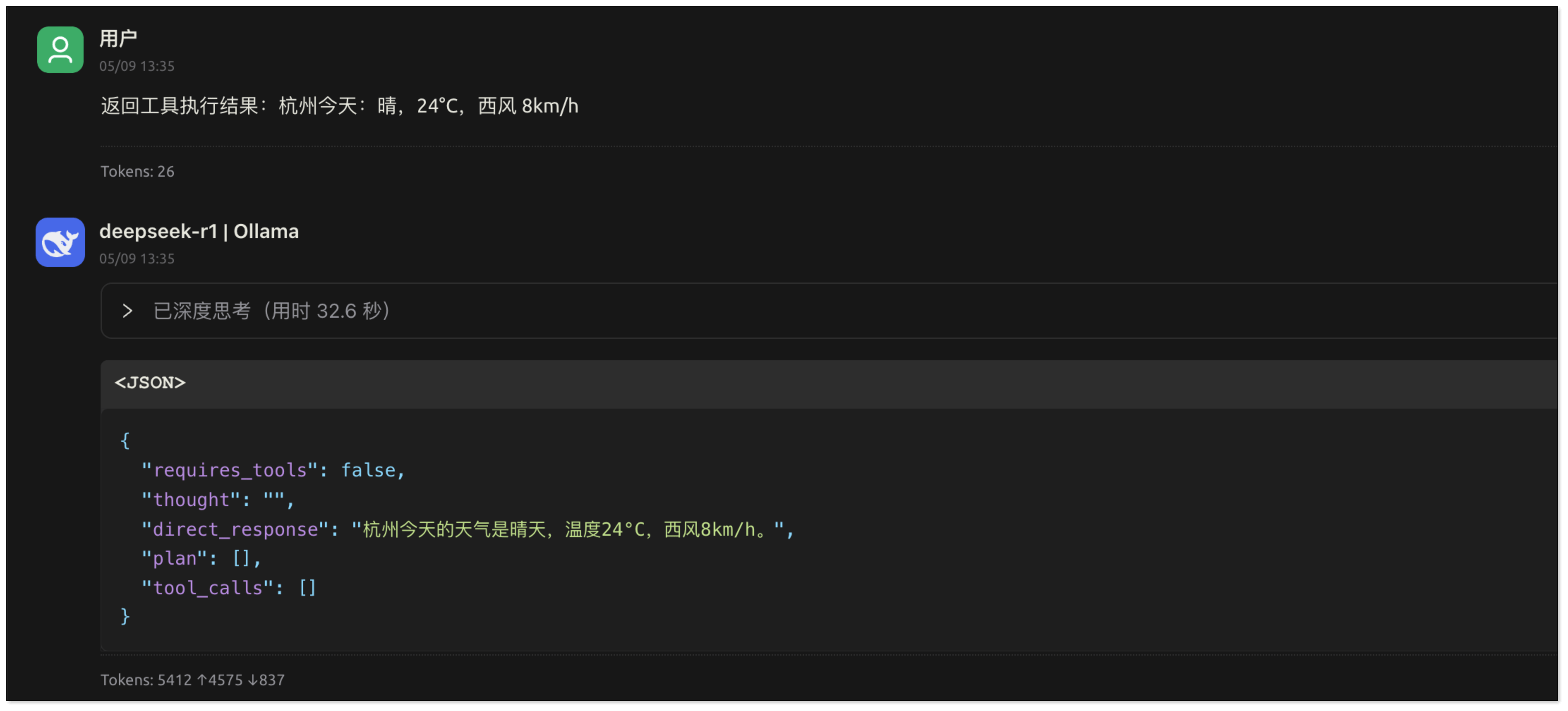
从本质上看,大语言模型通过其强大的自然语言理解(NLU)能力来解析用户的意图:明确用户想要完成什么任务,以及执行该任务需要哪些具体信息。模型会自动从对话历史和当前输入中提取出这些关键参数。随后,用户的应用程序可以根据模型提供的这些参数来调用相应的函数或 API 以完成实际操作,并将执行结果反馈给模型。最后,由模型整合所有信息,生成最终的、人性化的回复。
MCP:让模型更好地调用工具
Function Calling 解决了“模型如何调用开发者自定义的函数”这一核心问题,但在实际应用中,开发者们仍然可能面临一些挑战,例如:
- 如何优雅地处理由多个工具调用组成的复杂任务链(例如,先查询天气,再根据天气情况决定是否发送提醒邮件)?
- 如何建立一套规范化的工具参数结构,并实现工具的自动注册与发现?
- 如何适配并统一处理来自不同调用方式的请求(例如,通过 HTTP 接口调用,或作为本地插件执行)?
- 如何在不同的语言模型之间复用同一套经过良好设计的工具体系?
什么是 MCP?
MCP(Model Context Protocol,模型上下文协议) 是由 Anthropic 公司(Claude 模型的开发者)推出的一项开放标准协议。它旨在为大语言模型与外部工具(包括 API、函数、服务等)之间的通信提供一个通用的、标准化的接口。
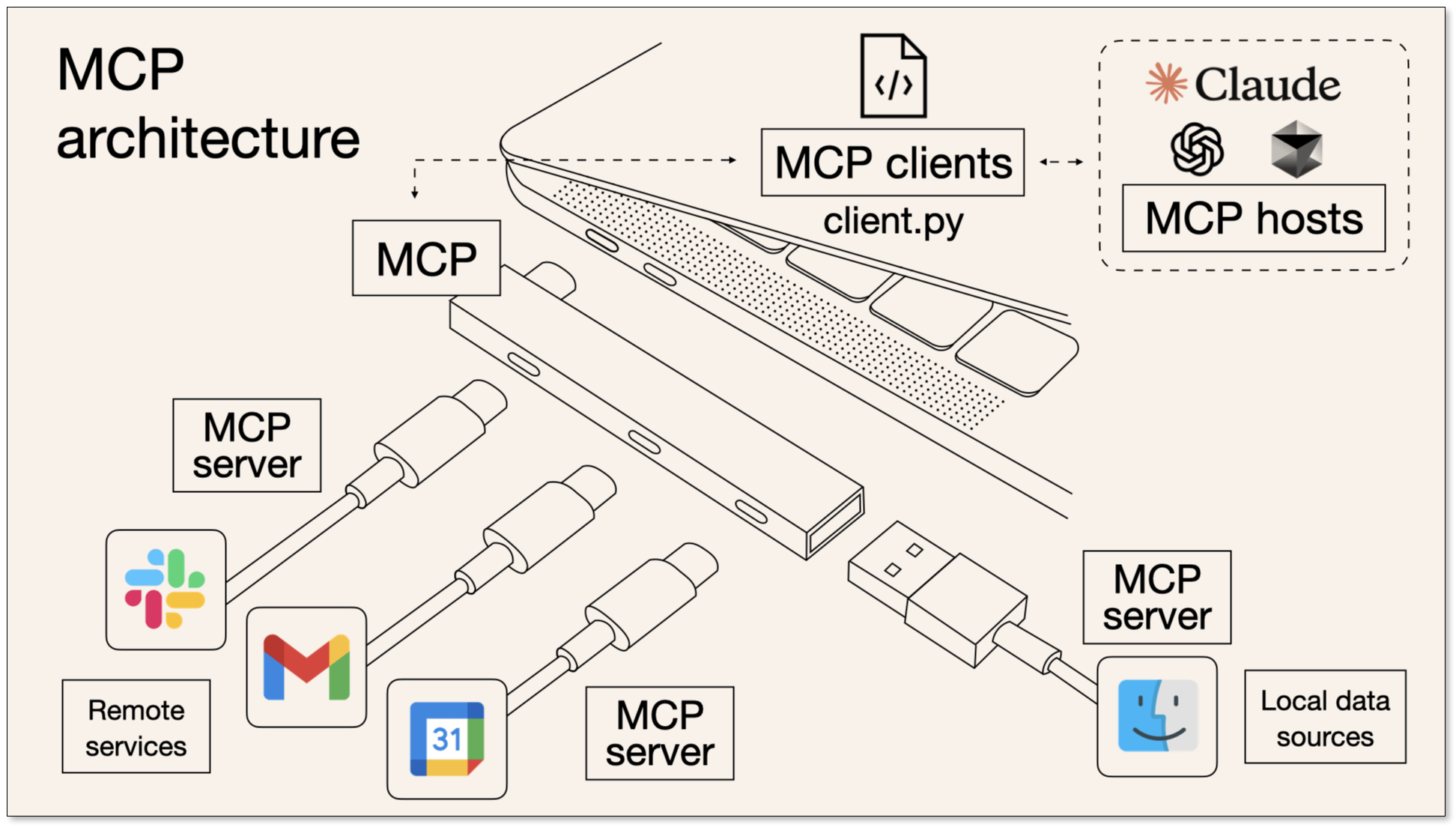
MCP 并非 Function Calling 的替代品,而是对其在工具执行层面的一种补充、规范和封装。它的目标是使整个工具调用系统更易于接入、更易于管理、也更易于在不同模型或应用间复用。
MCP 核心角色
MCP 的生态主要包含以下两个核心角色:
MCP Client(客户端)
- 通常是集成大语言模型的应用程序。
- 负责向 MCP Server 请求可用的工具列表。
- 当模型决定需要调用某个工具时,MCP Client 会使用 HTTP 或 stdio(标准输入/输出)等协议,向 MCP Server 发起具体的工具调用请求。
MCP Server(服务端)
- 负责实际执行工具逻辑的服务。
- 接收来自 MCP Client 的
tool_calls请求。 - 根据请求中指定的工具名称和参数,执行相应的工具函数或逻辑。
- 将工具的执行结果以统一的、结构化的格式返回给 MCP Client。
MCP Server 调用方式
MCP Server 支持多种调用方式,以适应不同的部署和使用场景。
HTTP 模式(StreamableHttp)
在这种模式下,MCP Server 作为一个 Web 服务运行,通常会暴露以下标准的 HTTP 接口:
/mcp:一个统一的端点,用于接收工具调用请求(通常是 POST 请求)或列出可用工具的请求。- 支持 Event Stream(事件流,用于流式响应)与 JSON-RPC 协议进行通信。
以下是一个基于 Node.js 和 Express 实现的天气服务 MCP Server(HTTP 模式)的演示代码:
cat > streamable_weather.mjs << 'EOF'
#!/usr/bin/env node
import express from "express";
import { McpServer, ResourceTemplate } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StreamableHTTPServerTransport } from "@modelcontextprotocol/sdk/server/streamableHttp.js";
import { z } from "zod";
const app = express();
app.use(express.json());
function getServer() {
const server = new McpServer({
name: "Weather",
version: "1.0.0"
});
server.resource(
"get_weather",
new ResourceTemplate("weather://{city}", { list: undefined }),
async (uri, { city }) => ({
contents: [{
uri: uri.href,
text: `Resource weather for ${city}: 晴,24°C`
}]
})
);
server.tool(
"get_weather",
{ city: z.string() },
async ({ city }) => ({
content: [{ type: "text", text: `Tool weather for ${city}: 明天晴,最高24°C,微风3km/h` }]
})
);
server.prompt(
"get_weather",
{ city: z.string() },
({ city }) => ({
messages: [{
role: "user",
content: {
type: "text",
text: `请告诉我 ${city} 的天气情况`
}
}]
})
);
return server;
}
app.post("/mcp", async (req, res) => {
try {
const server = getServer();
const transport = new StreamableHTTPServerTransport({
sessionIdGenerator: undefined,
});
res.on("close", () => {
console.log("Request closed");
transport.close();
server.close();
});
await server.connect(transport);
await transport.handleRequest(req, res, req.body);
} catch (error) {
console.error("Error handling MCP request:", error);
if (!res.headersSent) {
res.status(500).json({
jsonrpc: "2.0",
error: {
code: -32603,
message: "Internal server error",
},
id: null,
});
}
}
});
app.get("/mcp", (req, res) => {
console.log("Received GET MCP request");
res.status(405).json({
jsonrpc: "2.0",
error: {
code: -32000,
message: "Method not allowed.",
},
id: null,
});
});
app.delete("/mcp", (req, res) => {
console.log("Received DELETE MCP request");
res.status(405).json({
jsonrpc: "2.0",
error: {
code: -32000,
message: "Method not allowed.",
},
id: null,
});
});
const PORT = process.env.PORT || 30001;
app.listen(PORT, () => {
console.log(
`MCP Stateless Streamable HTTP Server listening on http://localhost:${PORT}/mcp`
);
});
EOF
使用示例:
# 安装依赖
npm install express @modelcontextprotocol/sdk zod
# 启动服务
node streamable_weather.mjs
# 获取工具列表
curl -N -X POST http://localhost:30001/mcp \
-H 'Accept: application/json, text/event-stream' \
-H 'Content-Type: application/json' \
-d '{
"jsonrpc":"2.0",
"id":1,
"method":"tools/list",
"params":{}
}'
# > 返回工具
# event: message
# data: {"result":{"tools":[{"name":"get_weather","inputSchema":{"type":"object","properties":{"city":{"type":"string"}},"required":["city"],"additionalProperties":false,"$schema":"http://json-schema.org/draft-07/schema#"}}]},"jsonrpc":"2.0","id":1}
# 执行工具调用链
curl -N -X POST http://localhost:30001/mcp \
-H 'Accept: application/json, text/event-stream' \
-H 'Content-Type: application/json' \
-d '{
"jsonrpc":"2.0",
"id":2,
"method":"tools/call",
"params":{
"name":"get_weather",
"arguments":{ "city":"北京" }
}
}'
# > 返回执行结果
# event: message
# data: {"result":{"content":[{"type":"text","text":"Tool weather for 北京: 明天晴,最高24°C,微风3km/h"}]},"jsonrpc":"2.0","id":2}
Stdio 模式(本地插件)
Stdio(Standard Input/Output)模式适用于将 MCP Server 作为本地插件程序运行的场景。在这种模式下,大语言模型(或其宿主应用)与 MCP Server 之间通过标准输入和标准输出进行通信,无需依赖网络连接。这种方式非常适合部署在受限环境或需要本地执行能力的场景。
以下是一个天气服务的 Stdio 模式演示代码:
cat > weather_stdio.mjs << 'EOF'
#!/usr/bin/env node
import { McpServer, ResourceTemplate } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
const server = new McpServer({
name: "Weather",
version: "1.0.0"
});
server.resource(
"get_weather",
new ResourceTemplate("weather://{city}", { list: undefined }),
async (uri, { city }) => ({
contents: [{
uri: uri.href,
text: `Resource weather for ${city}: 晴,24°C`
}]
})
);
server.tool(
"get_weather",
{ city: z.string() },
async ({ city }) => ({
content: [{ type: "text", text: `Tool weather for ${city}: 明天晴,最高24°C,微风3km/h` }]
})
);
server.prompt(
"get_weather",
{ city: z.string() },
({ city }) => ({
messages: [{
role: "user",
content: {
type: "text",
text: `请告诉我 ${city} 的天气情况`
}
}]
})
);
const transport = new StdioServerTransport();
await server.connect(transport);
EOF
使用示例:
# 获取工具列表
printf '{"jsonrpc":"2.0","id":1,"method":"tools/list","params":{}}\n' | node weather_stdio.mjs
# > 返回工具
# {"result":{"tools":[{"name":"get_weather","inputSchema":{"type":"object","properties":{"city":{"type":"string"}},"required":["city"],"additionalProperties":false,"$schema":"http://json-schema.org/draft-07/schema#"}}]},"jsonrpc":"2.0","id":1}
# 执行工具调用链:调用 get_weather
printf '{"jsonrpc":"2.0","id":4,"method":"tools/call","params":{"name":"get_weather","arguments":{"city":"北京"}}}\n' | node weather_stdio.mjs
# > 返回执行结果
# {"result":{"content":[{"type":"text","text":"Tool weather for 北京: 明天晴,最高24°C,微风3km/h"}]},"jsonrpc":"2.0","id":4}
MCP 多轮对话流程
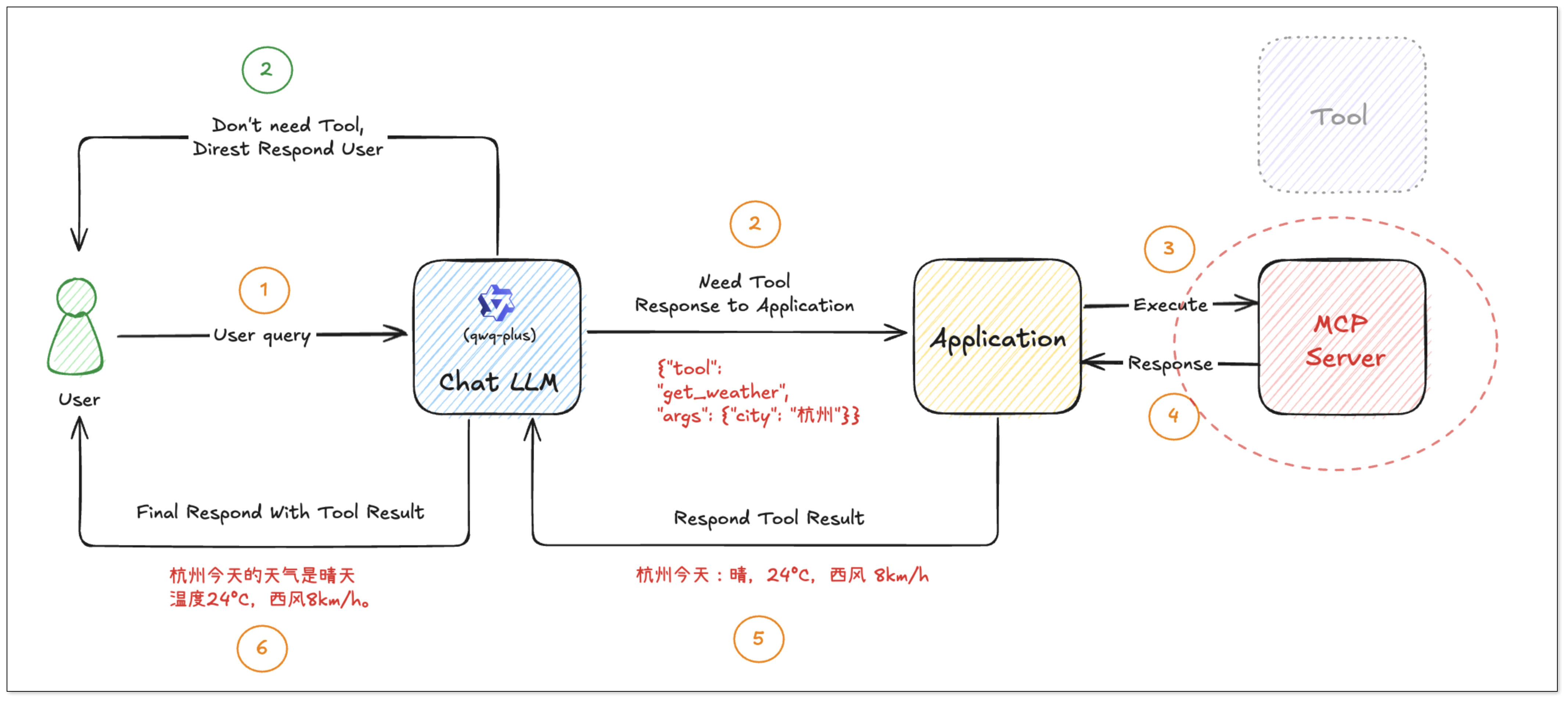
在多轮对话场景下,当用户输入:“北京天气如何?”
AI(MCP Client 的一部分)会识别出用户的意图是查询天气,并判断需要使用名为
get_weather的工具。随后,AI 会生成如下所示的结构化调用指令(通常遵循 Function Calling 的输出格式):{
"tool": "get_weather",
"args": {
"city": "北京"
}
}用户的应用程序(MCP Client)会将这个由 AI 生成的调用指令,按照 MCP 协议(例如 JSON-RPC over HTTP)转发至 MCP Server。MCP Server 接收到该调用请求后,会查找并执行名为
get_weather的工具,传入参数{"city": "北京"},并返回如下所示的结构化结果: (上图示例为 MCP Server 返回的 JSON 响应,其中 result.content[0].text 包含了工具执行的核心结果)
(上图示例为 MCP Server 返回的 JSON 响应,其中 result.content[0].text 包含了工具执行的核心结果)用户的应用程序(MCP Client)从 MCP Server 返回的响应中提取出有用的信息(例如,从
result.content[0].text中提取文本内容)。然后,它可以将这个原始的工具执行结果再次提交给大语言模型,让模型进行总结、润色,并生成最终面向用户的自然语言回复,例如:“明天北京天气晴朗,最高气温预计为24°C,伴有微风,风速大约3公里/小时。感谢您的咨询!如果还有其他问题,请随时提出。”
MCP 为大语言模型与外部世界(工具、API、服务)的交互提供了一个统一且可扩展的执行框架,其主要优势包括:
- 多种通信方式支持:灵活支持 HTTP、Stdio 等多种通信协议,适应不同部署需求。
- 统一的工具注册与声明:提供标准化的工具定义和描述机制,便于工具的管理和发现。
- 可复用的跨模型调用协议:使得同一套工具可以更容易地被不同的语言模型或应用所复用。
- 易于本地或远程部署:无论是本地插件还是远程服务,MCP 都能提供良好的支持。
通过将 Function Calling(定义模型如何“思考”并决定调用哪个工具)与 MCP(规范工具如何被“执行”并返回结果)相结合,我们为构建模块化、可编排、可维护的 AI Agent 系统打下了坚实的基础。
AI Agent:具备认知与行动能力的智能体
AI Agent(人工智能智能体) 可以被视为一个具备一定程度认知、决策、行动乃至反思能力的完整智能系统。它通常会整合前述的多种技术,例如:
- 使用 RAG 来从外部知识库获取和理解完成任务所需的背景知识。
- 使用 Function Calling 来解析用户意图、选择合适的工具并提取参数。
- 使用 MCP 作为统一的协议来与这些外部工具进行实际的交互和执行。
一个相对成熟的 AI Agent 通常能够表现出以下能力:
- 理解复杂目标:通过自然语言指令(例如,“帮我预订下周去北京出差的机票和酒店,预算在2000元以内,并把行程添加到我的日历”)来准确识别用户的核心意图和约束条件。
- 主动规划与任务拆解:能够将用户的复杂目标拆解为一系列可执行的子步骤,并按一定的逻辑顺序进行规划。
- 调用并协调外部工具:能够根据任务规划,自动选择并调用合适的外部工具(如 API、数据库、搜索引擎、代码解释器等)来执行具体的子任务。
- 记忆与利用上下文:能够理解并利用当前的对话历史、任务进展以及从工具调用中获取的信息,以指导后续的决策和行动。
- (部分高级 Agent)自我反思与调整:在执行过程中遇到失败或预期之外的结果时,能够进行一定程度的自我反思,尝试重试、调整计划或变更执行路径。
相较于传统的、主要以聊天和信息获取为目的的 AI,AI Agent 更像一个“可指挥、可编排、可行动”的智能执行者。它具备在真实应用场景中自主或半自主地解决复杂问题的潜力,因此在智能客服、数据分析与处理、自动化办公、个性化智能助理等领域展现出广泛的应用前景。
概念对比一览
为了更清晰地理解这些相关概念之间的区别与联系,下表进行了简要对比:
| 概念 | 本质 | 数据来源 | 适用场景 | 典型应用 |
|---|---|---|---|---|
| RAG | 检索 + 生成 | 外部知识库 / 文档 / 数据库 | 专业领域问答、动态知识更新、减少幻觉 | 企业智能知识库、智能客服机器人 |
| Function Calling | 模型驱动的外部函数/API调用决策 | 用户输入、对话上下文、预定义的工具集 | 实时数据交互、执行具体操作、自动化任务 | 天气查询、航班预订、订单处理 |
| MCP | 标准化的工具调用执行协议 | 任何可通过协议接入的多平台服务 | 跨模型/跨服务的工具复用与协作、标准化执行 | 智能工作流(如查天气+发邮件) |
| AI Agent | 自主规划 + 决策 + 执行的智能系统 | 综合运用(RAG + 工具调用 + 记忆等) | 复杂任务自动化、多步问题解决 | 个人智能助理、自动化流程机器人 |
总结
RAG、Function Calling、MCP 和 AI Agent 并非孤立存在的技术概念,而是在构建更强大、更实用的 AI 应用过程中,彼此协同、互为补充的关键组成部分。
RAG 增强了模型的知识获取能力,Function Calling 赋予了模型调用外部工具的决策能力,MCP 则为工具的执行提供了标准化的接口和协议,而 AI Agent 则是将这些能力有机整合,以期实现更高级别自主性和智能性的系统。理解并善用这些技术,将有助于我们开发出更贴近实际需求、更能解决复杂问题的下一代 AI 应用。