三大开源数据湖格式深度对比:Iceberg、Delta Lake 与 Paimon 全面解析
简述
在大数据时代,数据湖(Data Lake) 以其 低成本、灵活性和存算分离架构 成为数据管理的核心基础设施。
然而,传统数据湖存在两大痛点:
- 缺乏事务一致性(ACID):并发写入时容易造成数据不一致。
- 查询性能不稳定:随着数据量和小文件激增,元数据管理与 IO 成为瓶颈。
为了解决这些问题,新一代 数据湖表格式(Table Format) 在数据文件之上引入独立的 元数据层(Metadata Layer),实现了数据库级别的 ACID 事务、Schema 演进与快照隔离 功能。
目前行业主流的三大开源格式是:
- Apache Iceberg(Netflix & Apple 主导)
- Delta Lake(Databricks 推动)
- Apache Paimon(Flink 社区核心项目)
核心原理简析
元数据层
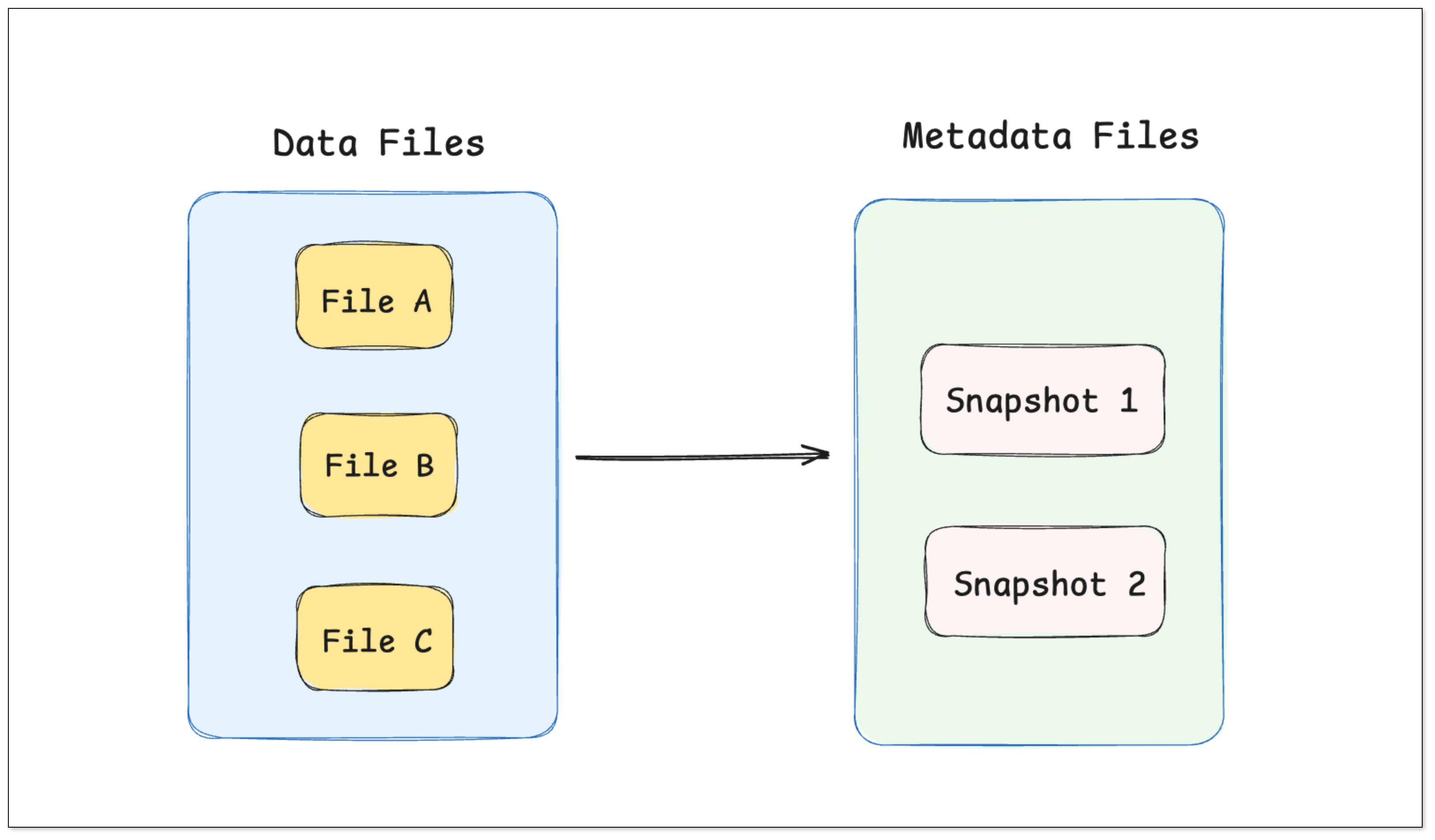
在数据湖架构中,元数据层是事务一致性与版本管理的核心。
每次写入或更新操作都会生成一个新的 快照(Snapshot),记录表的完整状态,包括:
- 当前活跃数据文件列表
- Schema 与分区信息
- 数据统计(行数、列 min/max、bloom filter)
查询引擎 只需定位到某个快照,即可读取一个一致的数据视图,从而实现:
- 读写分离
- 版本回溯
- 并发写入的一致性保障
数据写入
下面通过一个简单的例子来理解数据湖的核心原理,假设我们有一张用户表(users),要执行以下操作:
- 初始写入 2 条用户记录。
- 再插入 1 条新用户记录。
- 更新 1 条用户记录。
步骤一:写入 2 条用户记录
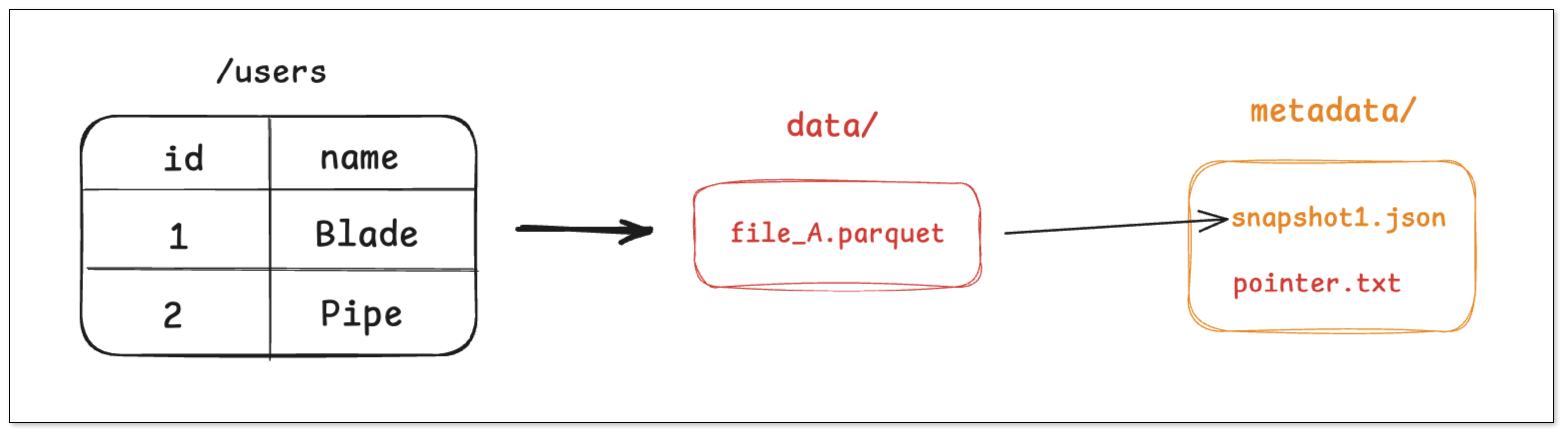
- 引擎将这两条记录写入到一个新的 Parquet 文件中,例如 file_A.parquet。
- 引擎创建一个元数据文件,记录下当前表的第一个快照(snapshot_1)包含了 file_A 这个文件。
- 最后引擎通过一次原子操作,将一个指针指向这个最新的 元数据文件。
任何查询 users 表的查询请求,都会先找到 pointer.txt,读取 snapshot_1,然后直接去访问 file_A。
步骤二:插入 1 条新记录
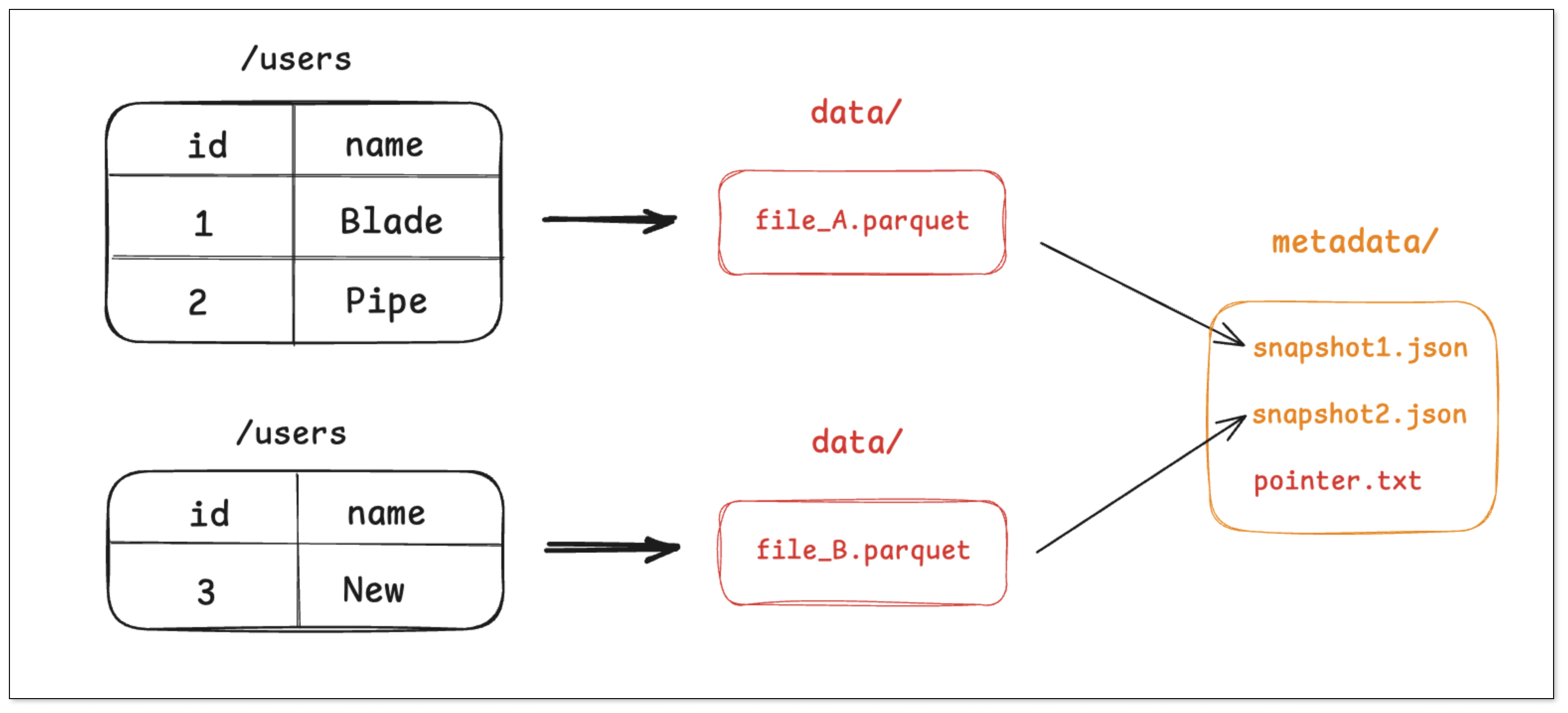
- 引擎将这条新记录写入一个新的 Parquet 文件 file_B.parquet。
- 引擎创建一个新元数据文件 snapshot_2.json,这个文件会记录当前最新状态(snapshot_2)由 file_A 和 file_B 两个文件组成。
- 通过原子操作,将 pointer.txt 指向 snapshot_2。
老的快照 snapshot_1** **依然存在,这为查询历史版本的数据提供了可能。
步骤三:更新数据与合并
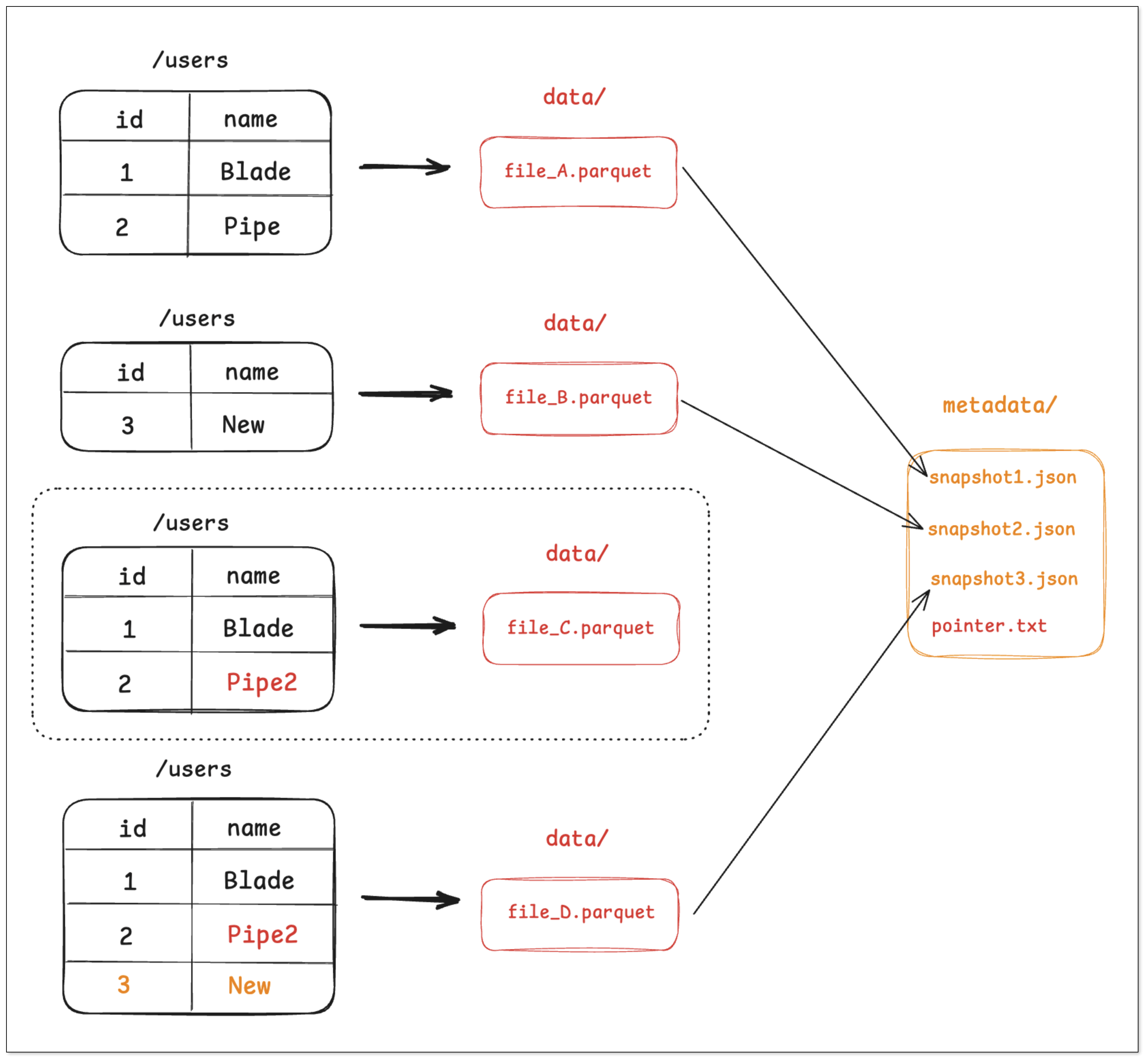
- 由于 Parquet 文件不可变,引擎需要读取 file_A 的内容,在内存中进行修改,然后将修改后的结果(连同未修改的数据)写入到一个新的 Parquet 文件 file_C.parquet。
- 同时,为了优化小文件问题,系统可能会触发一个合并(Compaction)任务,将 file_B 和 file_C 合并成一个更大的文件 file_D.parquet。
- 引擎创建 snapshot_3.json,记录当前最新状态只由 file_D 组成。
- 最后,原子地更新 pointer.txt 指向 snapshot_3。
在这个过程中,不再被最新快照引用的文件(如 file_A,file_B)会成为“孤立文件”,并由后台垃圾回收机制清理。这种设计将复杂的数据操作,转化为了对元数据文件的原子操作,从而保障了事务的 ACID 特性。
数据查询
查询时,引擎会经历以下步骤:
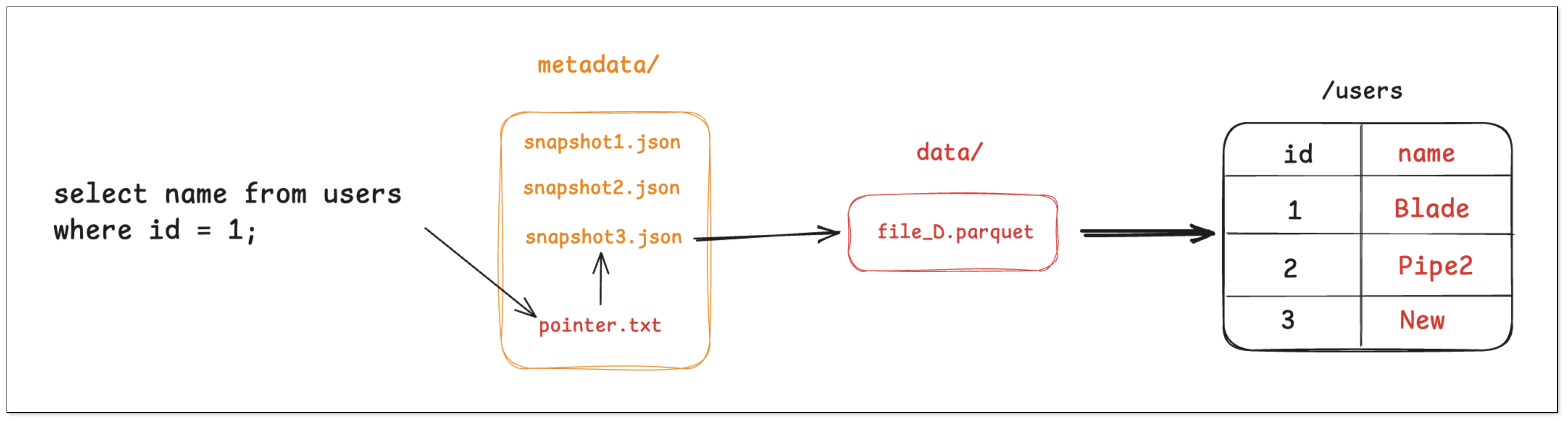
- 先读取 pointer.txt,解析到当前最新快照或用户指定的历史快照。
- 从快照拿到要扫描的数据文件列表与其统计信息(分区、行数、列 min/max、行组统计、bloom 过滤器等)。
- 基于谓词做 分区裁剪 与 列统计裁剪,只保留可能命中的文件或行,并做 列裁剪与谓词下推 到 Parquet/ORC。
- 合并读取文件
- CoW:直接读取被选中的最新文件。
- MoR:读取 文件 + 增量/删除向量文件,在读取阶段完成 合并与应用删除。
综上,数据湖的本质是将复杂的数据操作转化为对元数据的原子操作,从而实现 ACID 事务与高效查询。接下来,我们将进一步对比 Iceberg、Delta Lake 与 Paimon 的实现差异。
Iceberg vs Delta vs Paimon
虽然核心思想相似,但 Iceberg、Delta Lake 与 Paimon 在元数据结构、设计思路上存在显著差异,下面我们从几个核心维度进行更具体的对比。
| 特性 | Apache Iceberg | Delta Lake | Apache Paimon |
|---|---|---|---|
| 核心理念 | 开放标准、引擎解耦 | 日志驱动、事务一致 | 流批一体、实时更新 |
| 元数据结构 | 树状结构(Metadata → Manifest List → Manifest) | 线性事务日志(JSON + Parquet Checkpoint) | LSM-Tree 层级结构 |
| 事务机制 | ACID + 乐观并发控制 (OCC) | ACID + 事务日志 | ACID + 主键去重合并 |
| 最佳场景 | 批量分析、多引擎共享 | Spark 主导场景 | 实时 CDC 与流批一体 |
| 生态兼容性 | Spark、Flink、Trino、StarRocks | Spark / Databricks | Flink、Spark、Hive |
| 性能优化 | 高效裁剪与快照合并 | 自动优化 + ZORDER 排布 | 后台 Compaction 合并 |
| Schema 演进 | 强大(字段增删改均支持) | 较好(有限制) | 灵活(自动合并模式) |
Iceberg
元数据结构
Iceberg 采用 三层树状元数据结构,使得大规模元数据剪枝成为可能:
- Metadata 文件:记录表结构与快照索引。
- Manifest List:快照的文件索引层。
- Manifest 文件:包含每个数据文件的详细统计(min/max、分区范围等)。
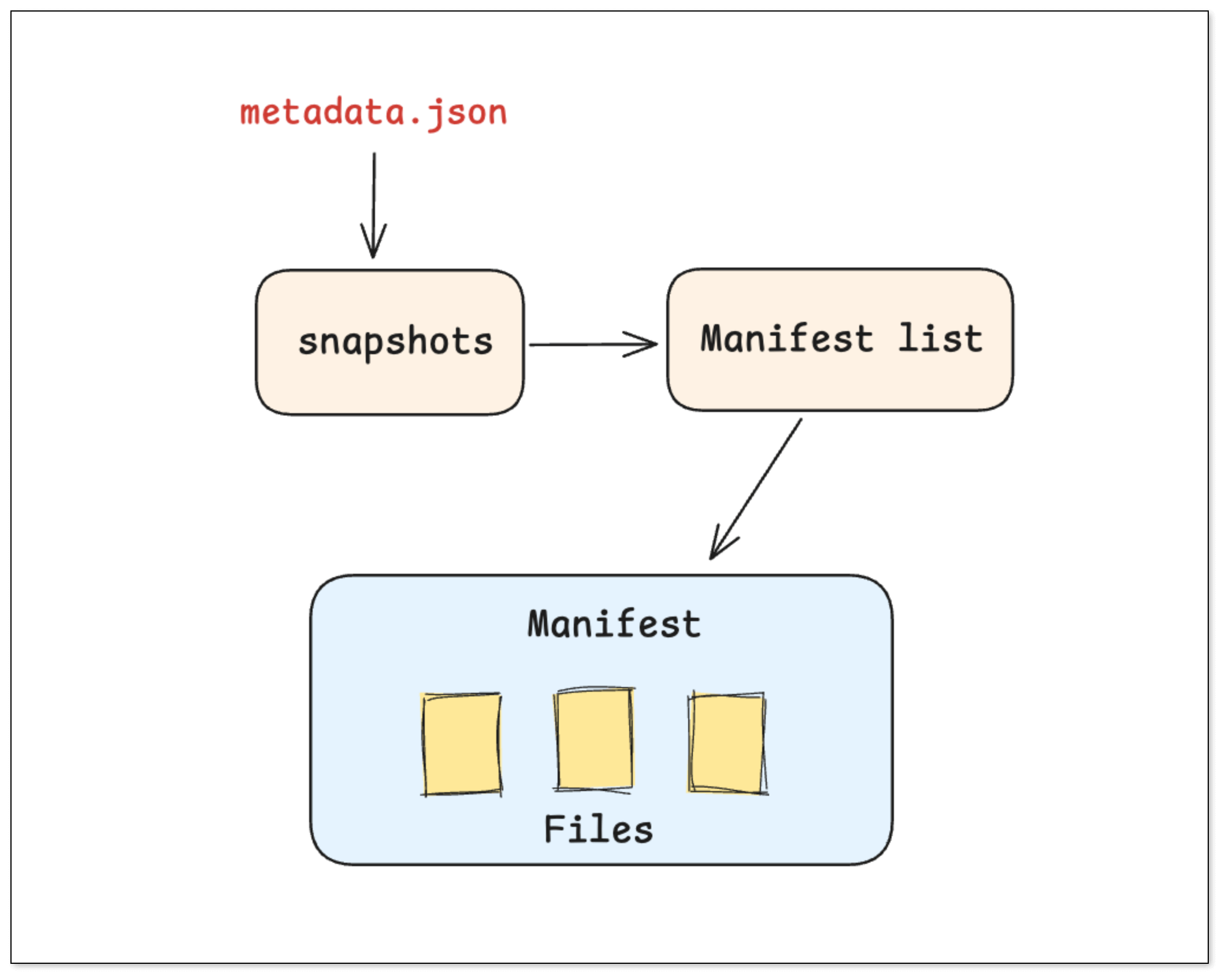
更新机制
Iceberg 支持 Delete File 模型:
- 删除操作会生成新的 del_file_A.parquet,记录被删除行的信息。
- 查询时自动根据 Delete 文件过滤行,实现 Merge-on-Read(MoR)。
查询性能
引擎可先筛选 Manifest List,再读取对应数据文件,实现:
- 高效分区裁剪
- 列级统计下推
- 最小 IO 成本的文件扫描
Delta Lake
事务日志机制
Delta Lake 的核心是一套严格按时间顺序排列的 事务日志(_delta_log/),用于记录表的每一次变更。
- 事务日志 (Transaction Log):每一次对表的写入、更新或删除,都会生成一个新的 JSON 文件,清晰地记录了本次操作 增加 了哪些文件,删除 了哪些文件。
- 检查点文件 (Checkpoint):当事务日志积累过多时,Delta Lake 会将之前的状态合并成一个 检查点文件,在查询时就不需要从头读取所有日志,只需从最近的 检查点 开始读取即可。
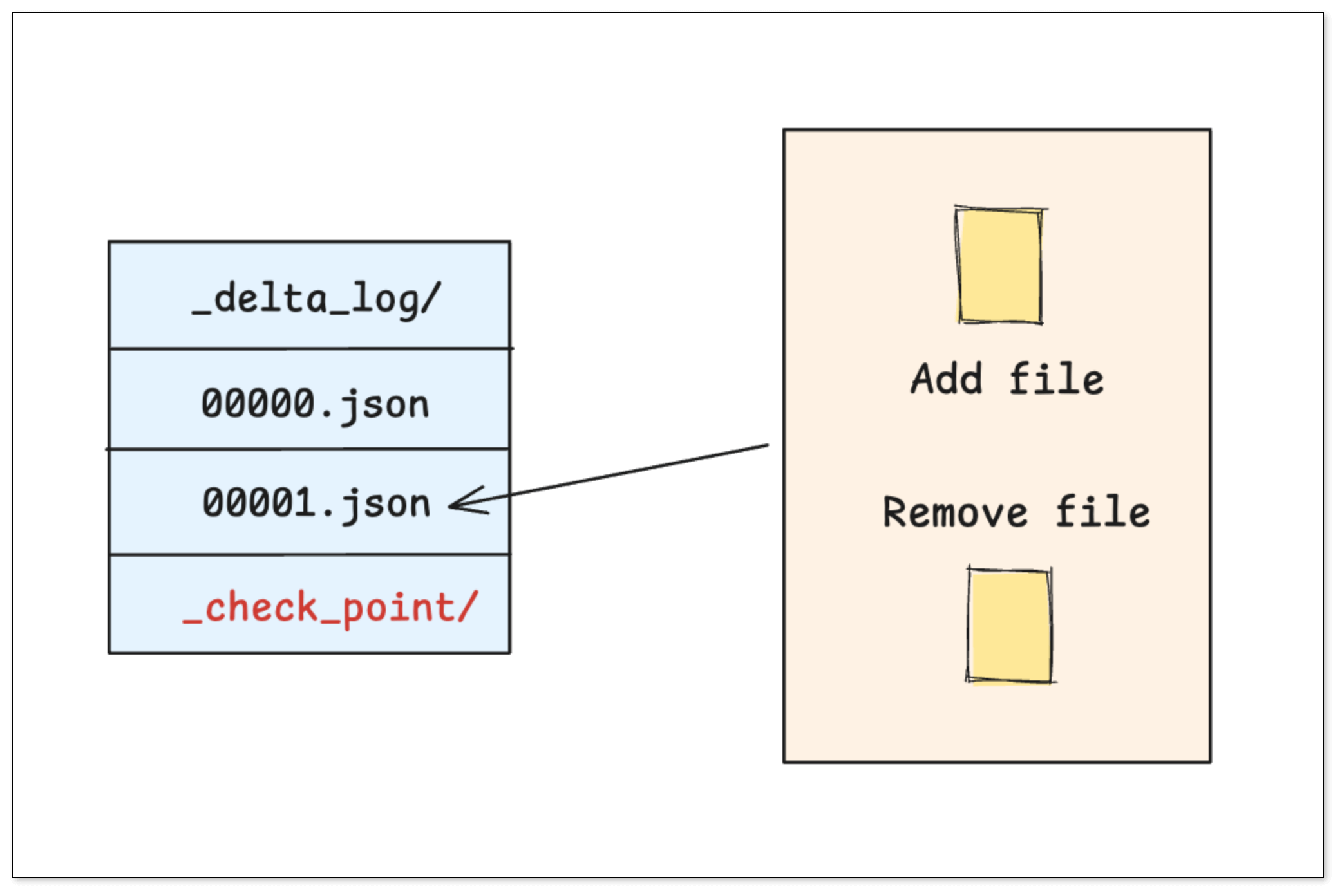
更新数据
Delta Lake 的核心是 _delta_log/ 文件夹,存放有序 JSON 事务日志。
- 每次写入、更新或删除操作都生成一个日志文件。
- 当日志积累到一定量后,合并为 Checkpoint(Parquet 格式) 提升查询效率。
更新模型
- Copy-on-Write(CoW):更新即重写文件,简单直观。
- Delete Vector:通过行级标记进行逻辑删除,避免频繁重写。
查询恢复
- 查询引擎先从最新 Checkpoint 恢复表状态,再顺序应用后续日志,快速构建出一致数据视图。
Paimon
元数据与存储结构
Paimon 借鉴 LSM-Tree 思想,将数据按层次存储:
- L0 层:快速写入层(实时数据流入)
- L1/L2 层:后台合并层(去重与排序)
通过持续 Compaction,保持高吞吐与低延迟。
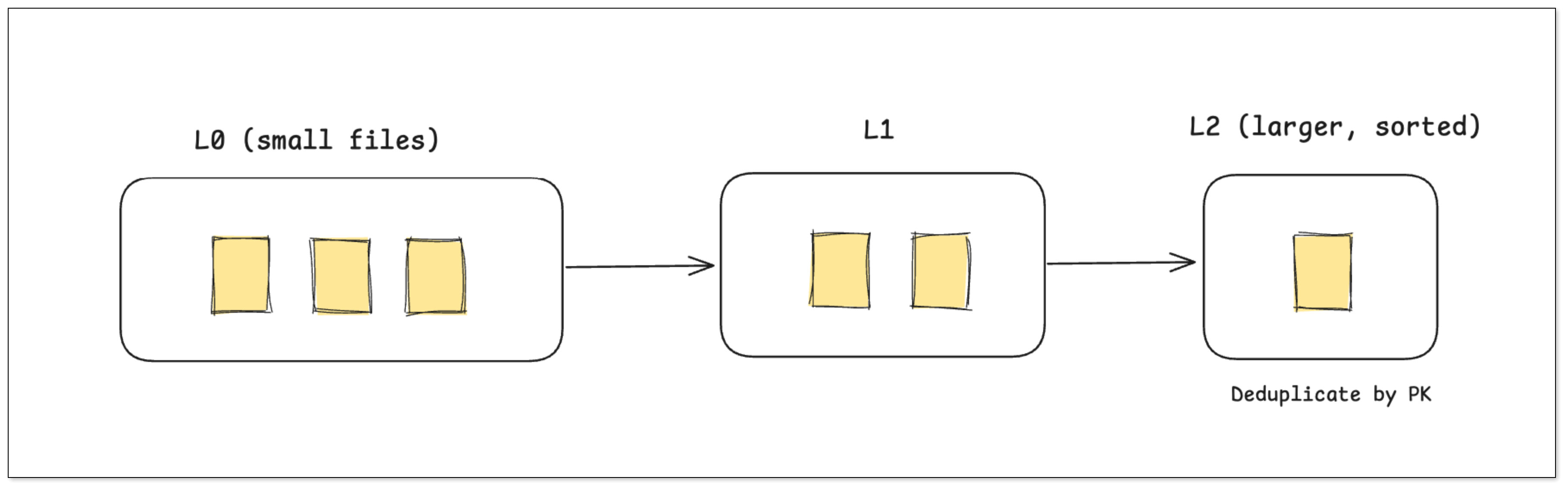
实时更新与合并
更新操作直接写入新的 L0 文件,后台自动合并并去重,确保:
- 主键唯一性
- 低延迟的增删改性能
典型场景
Paimon 与 Flink CDC 深度整合,天然支持 Upsert 与 流式 Join,非常适合:
- 实时数仓
- CDC 数据同步
- 流批一体架构
计算瓶颈的演变
虽然三者的 ACID 与快照机制 原理相似,但它们在元数据管理与计算优化上存在瓶颈差异:
| 模型 | 优点 | 潜在瓶颈 |
|---|---|---|
| CoW(写时合并) | 数据一致性强 | 高频更新触发文件重写 |
| MoR(读时合并) | 写入轻量 | 查询阶段合并压力大 |
| LSM 分层(Paimon) | 低延迟、高并发 | 后台合并成本高 |
为解决这些问题,主流云厂商推出托管优化方案:
- AWS Glue + Iceberg:自动小文件合并与表优化。
- Databricks Delta Lake:后台
OPTIMIZE、ZORDER自动调优。 - 阿里云 DLF + Paimon:支持存储优化与后台 Compaction 调度。
常见问题
Q1:为什么数据湖格式需要支持 ACID?
A:ACID 事务确保在并发写入和失败恢复时数据一致,避免“脏读”与不一致状态。
Q2:Iceberg、Delta Lake、Paimon 都能支持实时更新吗?
A:Paimon 在实时更新上最强,Iceberg 与 Delta 也在持续增强 MoR 模式以支持流式写入。
Q3:如何选择合适的湖格式?
- Spark 为主:Delta Lake
- 多引擎分析:Iceberg
- 实时流批:Paimon
Q4:这三种格式都能运行在对象存储(如 S3、OSS)上吗?
A:是的,它们都支持分布式对象存储,并兼容存算分离架构。
Q5:Schema 演进是否会导致旧数据读取失败?
A:不会。现代格式通过快照与字段映射确保兼容性。
Q6:能否跨引擎读取同一张表?
A:Iceberg 与 Paimon 都可实现,Delta 需要特定兼容层支持。
总结
| 格式 | 适用场景 | 技术亮点 |
|---|---|---|
| Apache Iceberg | 多引擎分析、批量场景 | 强大 Schema 演进与查询优化 |
| Delta Lake | Spark 环境、数据工程 | 事务日志简单直观,生态完善 |
| Apache Paimon | 实时数仓、流批一体 | LSM 架构与实时 Upsert 支持 |
Iceberg、Delta Lake 与 Paimon 展示了数据湖在不同场景下的技术路径,企业可根据业务特点灵活选型,总体而言:
- 想构建 多引擎共享的企业级数据湖,选 Iceberg
- 想在 Databricks/Spark 生态中简化管理,选 Delta Lake
- 想实现 实时数仓与流批一体架构,选 Paimon